
「数千行ある名簿から、特定の条件の人だけを抜き出したい」「売上順に並べ替えたいけれど、元の表の順番は変えたくない……」そんな悩みはありませんか?
Googleスプレッドシートの「FILTER」「SORT」「UNIQUE」をマスターすれば、こうしたデータ加工はすべて自動。まるで魔法のように、あなたが欲しいデータだけが整理された状態で表示されます。
ボタン操作による並べ替えも便利ですが、「関数」を使う最大のメリットは、元のデータを書き換えても抽出結果が自動で更新されることにあります。この記事では、初心者の方でも今日から実務に組み込めるよう、これら3つの関数の基本から「エラーを出さないコツ」までを徹底解説します!
FILTER関数
基本的な使い方
構文=FILTER(範囲, 条件1, [条件2, …])
ソース範囲をフィルタ処理して、指定した条件を満たす行または列のみを返します。
範囲を選択して、指定した条件に合う行または列を表示させます。「FILTER関数」のポイントは、単一の行や列ではなく、複数の行や列を表示させることが出来るところにあります。実際にどのように使うかは以下で詳しくご説明させて頂きます。
実際の使い方
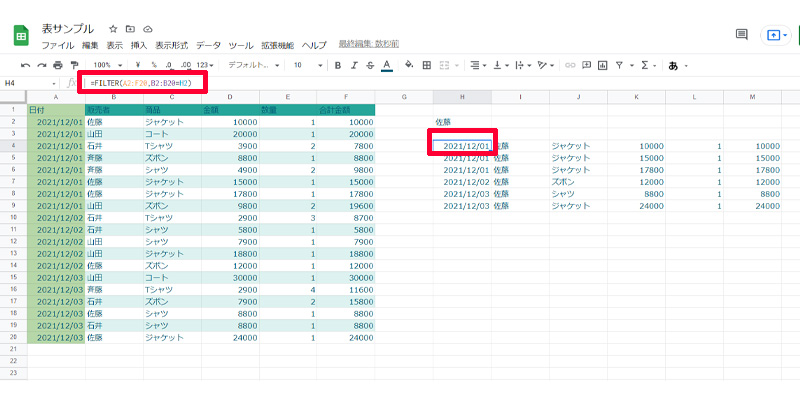
12月の売り上げ表から、佐藤さんが購入した商品等の情報をすべて表示させます。数式は以下になります。
=FILTER(A2:F20,B2:B20=H2)
「A2:F20」で選択範囲を指定して、「B2:B20」の列の中で、「H2」に合う行を表示させています。
ここで注意して頂きたいのは、「FILTER関数」は、「見出し」を含むことが出来ないので、日付や購入者と書かれた部分が必要であれば、ご自身でコピーアンドペーストして追加するようにしてください。選択範囲を「A1:F20」と入力するとエラーになってしまいますので注意が必要です。また「H2」は、「”佐藤”」と文字列にしても同じ結果が表示されます。
応用編
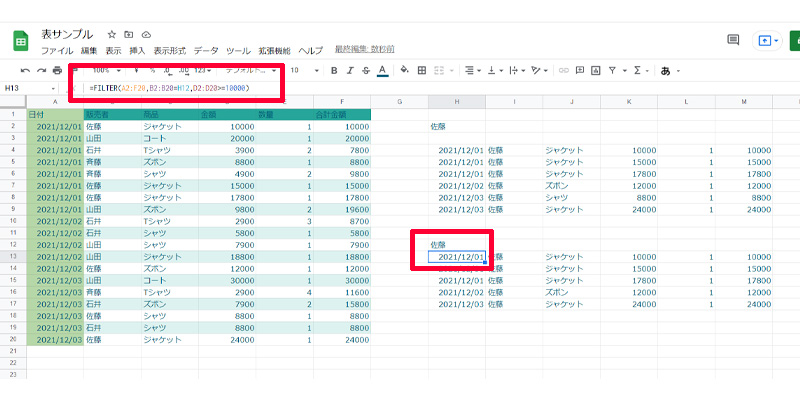
「FILTER関数」は単一の条件だけではなく、複数の条件を指定することも可能です。先程の条件に、10000円以上という条件を追加してみました。数式は以下になります。
=FILTER(A2:F20,B2:B20=H12,D2:D20>=10000)
先程の数式の後に、「 ,D2:D20>=10000 」を追加しています。最初に表示されていた、「シャツ8800円」の列が消えています。
「FILTER関数」で間違いやすいポイントが、選択範囲の行番号(数字)は同じである必要があるということです。ここでは、「 A2:F20」、「B2:B20」、「D2:D20」 のように、セルの「列」は違っても、「行」はすべて同じになっています。「行」が1つでも違うとエラーになりますので注意して利用してください。
上級テクニック
先ほど、「見出しはコピー&ペーストする必要がある」と記載させて頂きましたが、この問題を一気に解決する方法があります。「見出しとFILTERの結果を結合させて一気に表示させる方法」をご紹介させて頂きます。
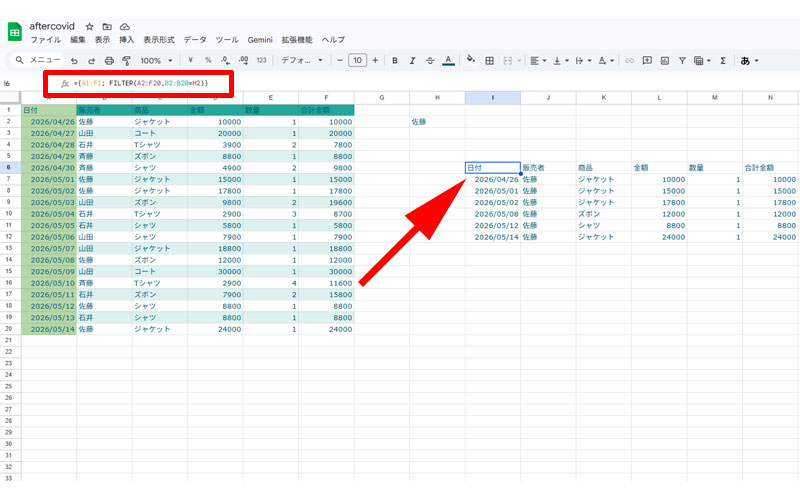
数式は以下になります。
={A1:F1; FILTER(A2:F20,B2:B20=H2)}
この場合、見出しが A1:F1 にあり、データが A2:F20 にあります。
この数式の仕組み
- { }(中カッコ): 複数の範囲を一つのカタマリとして扱う「配列」の合図です。
- A1:F1: 最初に表示させたい「見出し」の範囲です。
;(セミコロン): データを「改行(縦に結合)」するという意味です。- FILTER(…): 2行目以降に流し込む抽出データです。
中カッコ内でのつなぎ方には2種類あります。用途に合わせて使い分けますが、今回のように「見出しの下にデータを並べる」場合はセミコロンを使います。横に並べる場合はカンマを使います。
使う時の注意点
1, 列数を合わせる 見出しが「AからFまで(6列)」なら、FILTERで抽出する範囲も必ず「6列」にする必要があります。列数がズレていると #VALUE! エラーになります。
- OK: {A1:F1 ; FILTER(A2:F20, …)}(どちらも6列)
- NG: {A1:E1 ; FILTER(A2:F20, …)}(5列と6列でズレている)
2, データがない時のエラー対策 FILTER関数は、条件に合うデータが1件もないと #N/A エラーを返します。このとき、中カッコを使っていると見出しまで消えてエラー表示になってしまいます。 これを防ぐために、以下のように IFERROR 関数と組み合わせるのがプロの書き方です。
={A1:F1; IFERROR(FILTER(A2:F20, B2:B20=”佐藤”), “該当データなし”)}
SORT関数
基本的な使い方
構文=SORT(範囲, 並べ替える列, 昇順, [並べ替える列2, 昇順2, …])
指定した配列または範囲の行を、1 列または複数の列の値に従って並べ替えます。
範囲を選択して、昇順、または降順で並べ替えます。
- 昇順:TRUE
- 降順:FALSE
実際にどのように使うかは以下で詳しくご説明させて頂きます。
実際の使い方
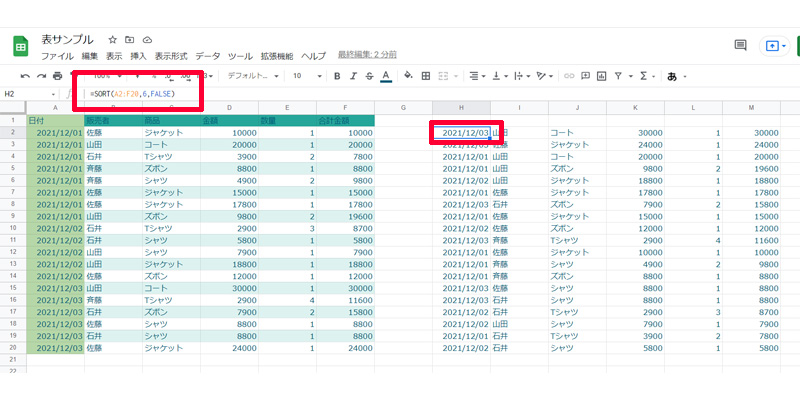
12月の売り上げ表から、合計の売上金額順に並び替えています。数式は以下になります。
=SORT(A2:F20,6,FALSE)
「A2:F20」で範囲を指定して、「6」で列を指定しています。並び替えは昇順にしていますので、「FALSE」が入ります。列は、範囲を指定しても同じ結果が表示されます。(この場合は、F2:F20)
なお、条件を追加して計算することも可能です。この表では単価も考慮した並び替えを指定すると、合計の売上金額が同額の場合、単価の高い順や低い順で並び替えることも可能です。
=SORT(A2:F20,6,FALSE,4,FALSE)
単純な並び替えの場合
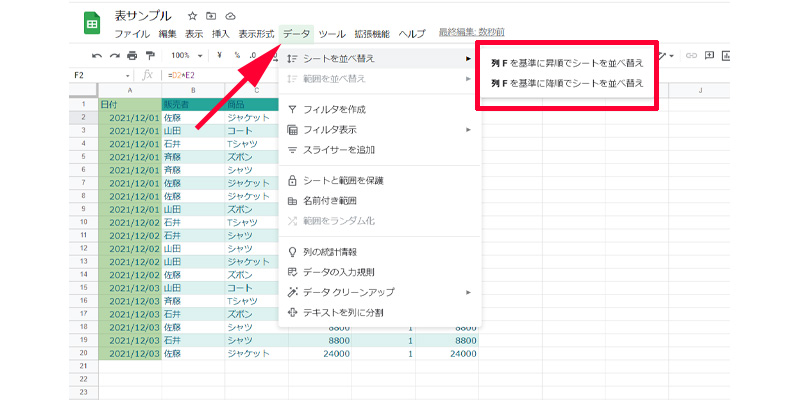
単純に表の並び替えを行う場合は、「SORT関数」を使うよりも、データの並び替えを使ったほうが簡単です。並び替える列のセルを選択して、メニューバーから「データ」→「シートを並び替え」→「昇順または降順」を選択します。
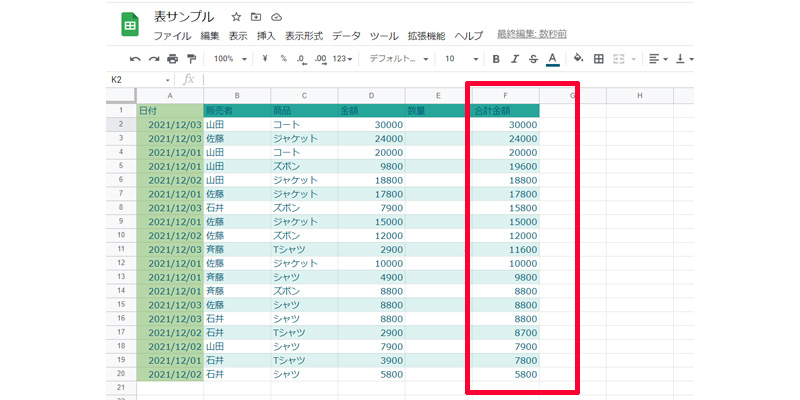
「降順」を選択すると、合計の売上金額が大きい順に並べ替えられました。
応用編
先ほどSORT関数の使い方として、「=SORT(A2:F20,6,FALSE)」とご紹介しました。この中で第2引数(並べ替える列)を「6」としました。これは指定した範囲の左から数えて「6番目の列」という意味です。この記載方法はある意味わかりやすく、簡単な表や今後変更することのない表には有効な方法なのですが、今後表に編集を加えたりする場合は、問題が発生する場合があります。
例えば、「担当者と商品の間に、『商品コード』という列を1列挿入したい」となった時、どうなるのでしょうか?
- 元の「売上合計」は、左から数えて7番目に移動してしまいます。
- しかし、数式の「6」はそのままなので、新しく入った「単価」などの別の列を基準に並べ替えられてしまうのです。
これが「数式が壊れる(意図した結果にならない)」という状態です。このようなことにならないようにするために「列全体を範囲指定」する方法があります。
=SORT(A2:F20, F2:F20, FALSE)
この書き方のすごいところは、列を挿入してもスプレッドシートが自動で数式を書き換えてくれる点です。
- 列を1列挿入すると、F列だった「売上合計」はG列に移動します。
- このとき、スプレッドシートは賢いので、数式を自動的に =SORT(A2:G20, G2:G20, FALSE) に更新してくれます。
結果として、列が増えても減っても、常に「売上合計」を基準に並べ替え続けてくれるのです。メンテナンス性が格段に上がりますので、ぜひこの数式を使うように心がけてください。
UNIQUE関数
基本的な使い方
構文=UNIQUE(範囲)
重複する行を破棄して、指定したソース範囲内の一意の行を返します。行はソース範囲内の先頭から順に返されます。
重複するデータを削除する関数になります。実際にどのように使うかは以下で詳しくご説明させて頂きます。
実際の使い方
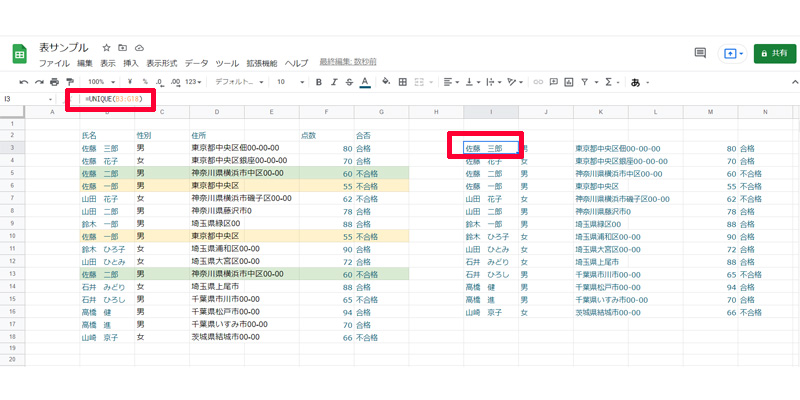
住所録から重複したデータを削除します。重複したデータは色を塗ってある2件、「佐藤一郎・佐藤二郎」になります。数式は以下になります。
=UNIQUE(B3:G18)
数式はとてもシンプルで、範囲を選択するだけになります。
UNIQUE関数を使わないで重複を削除する
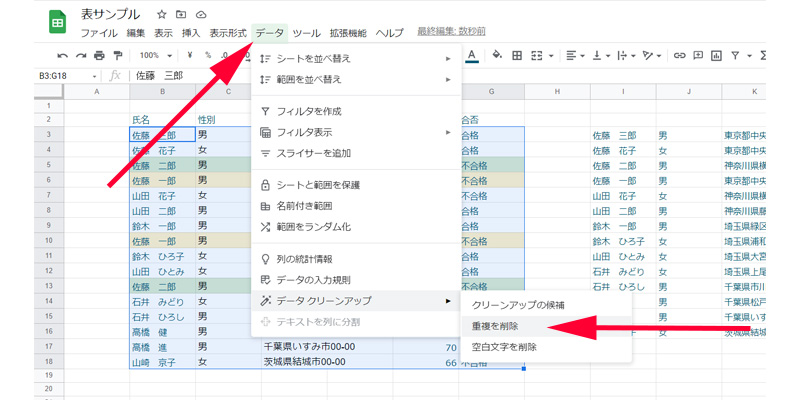
「重複の削除」は、「UNIQUE関数」を使わないでも削除することが出来るようになっています。
表の範囲を選択したら、メニューバーから「データ」→「データ クリーンアップ」→「重複を削除」を選択します。
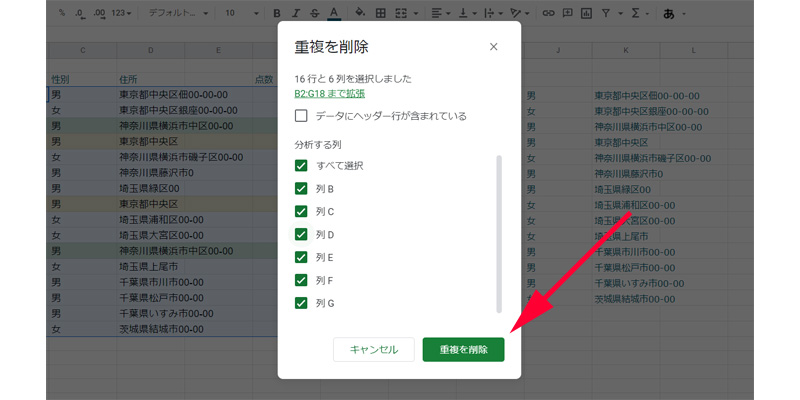
分析する列を指定します。選択が終わったら、「重複を削除」をクリックします。
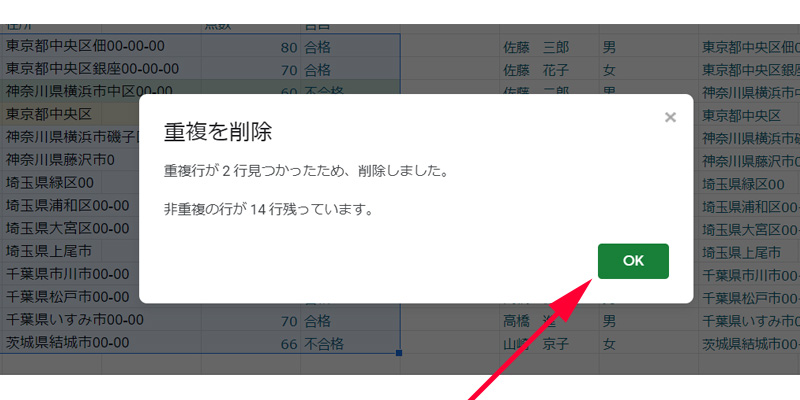
ここでは重複が2行見つかったと表示しています。そのまま「OK」をクリックします。
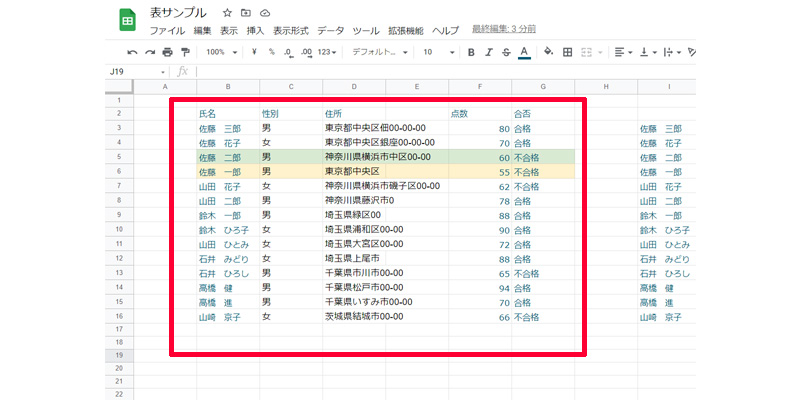
重複していた「行」が無事削除されました。
「UNIQUE関数」を使うか、「データ→重複を削除」を使うかは、元のデータが必要か不要かによって使い分けるのが良いかと思います。
マスターが教える「プロの時短」Tips
エラー「#REF!」への対策
これらの関数は「結果を書き出す先にすでに文字が入っている」と、展開できずにエラー(#REF!)になります。「関数の右側と下側は空けておく」という鉄則を覚えておきましょう。
関数のネスト(組み合わせ)
「=SORT(FILTER(A:F, B:B=”佐藤”), 6, FALSE) のように、FILTERの結果をさらにSORTにかけることができます。これができるようになると、スプレッドシートの活用レベルが一気に跳ね上がります!」
ワイルドカードの活用
「FILTER関数でも『*(アスタリスク)』は使えますが、少し特殊な書き方(REGEXMATCH関数などとの併用)が必要です。まずは完全一致から慣れていきましょう。」
「データクリーンアップ」との使い分け
「一時的にデータを整理して終わりならメニューの『重複を削除』、常に最新のデータを表示し続けたいなら『UNIQUE関数』。この使い分けが、管理しやすいシート作りのコツです。」
まとめ
お疲れ様でした!データ抽出・並べ替え・重複削除という、スプレッドシートで最も頻繁に行われる作業を自動化する3つの関数をご紹介しました。
- 条件に合うものだけ抜きたいなら、FILTER関数
- データの順番を入れ替えたいなら、SORT関数
- ダブりをなくしてスッキリさせたいなら、UNIQUE関数
これらを組み合わせれば(例えば、UNIQUEで重複を消した後にSORTで並べ替えるなど)、手作業では不可能なスピードと正確さでレポートを作成できます。
「関数でやるか、メニューボタンでやるか」の基準は、「その作業を明日も繰り返すかどうか」です。一度数式を組んでしまえば、明日からのあなたの作業時間はゼロになります。ぜひ、ご自身のシートでその快感を味わってみてください!
今回も最後までお読みいただき、ありがとうございました。


コメント