
「名簿の『氏名』を『姓』と『名』に分けたい……」「商品名の余計な文字を一括で消したい……」 そんな作業、まさか一つずつ手入力していませんか?
Googleスプレッドシートの「テキスト関数」を使いこなせば、何百行、何千行あるデータ編集も、数式ひとつで一瞬で終わります。
この記事では、文字の「判定」「検索」「抽出」「分割」「置換」という、実務で頻出する5つのシーンに分けて、最強の関数たちを分かりやすく解説します。これらをマスターして、地味で退屈な入力作業から卒業しましょう!
EXACT関数
基本的な使い方
構文=EXACT(文字列1, 文字列2)
2 つの文字列が同一であるかを検証します。
説明を読んだ通りの機能です。2つの文字列が同じかどうか判断します。実際にどのように使うかは以下で詳しくご説明させて頂きます。
実際の使い方
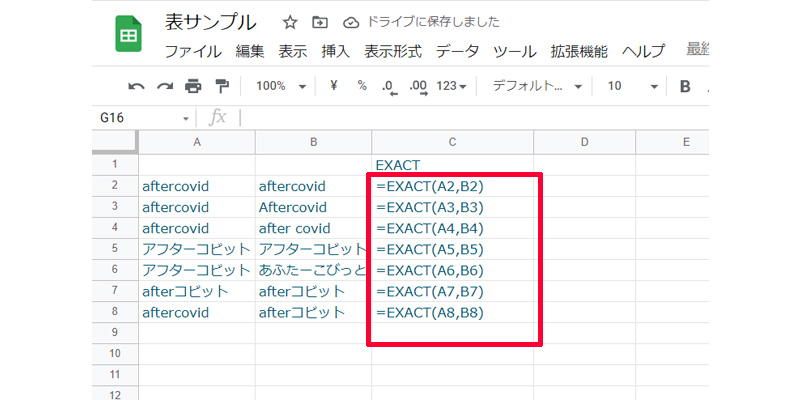
列Aと列Bの文字列が同じかどうか判断します。数式は以下になります。
=EXACT(A2,B2)
「EXACT関数」は、文字列が同じであれば、「TRUE」を違う場合は、「FALSE」を返します。
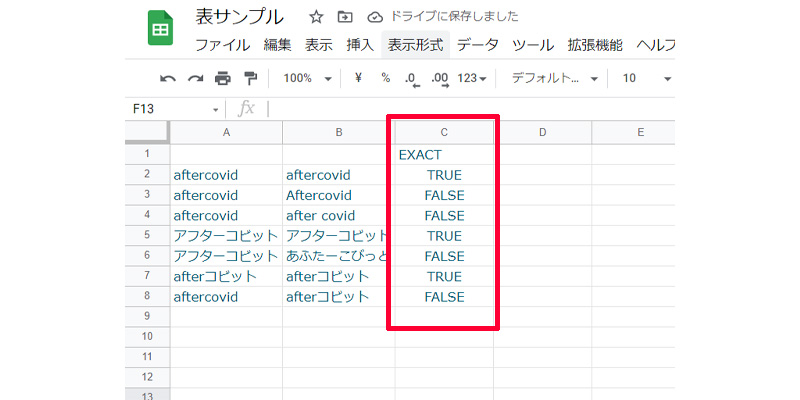
完全一致であれば「TRUE」を返しているのが分かると思います。1語でも大文字になっていたりしたら、「FALSE」を返しています。
「EXACT関数」以外にも文字列が一致しているかどうかを判断する方法があります。「IF関数」、または単純に「=」を使う方法です。しかし計算結果は「EXACT関数」とは違うものになりますので、何が違うのか、その違いについてみていきましょう。
他の方法との比較
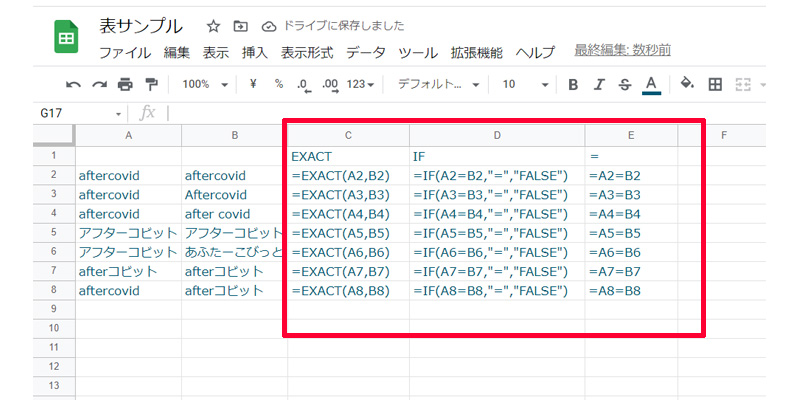
- EXACT関数:=EXACT(A2,B2)
- IF関数:=IF(A2=B2,”=”,”FALSE”)
- =:=A2=B2
それぞれ数式を挿入してみました。「IF関数」のみ、正しい時は「”=”」、違う時は「”FALSE”」と指定しています。
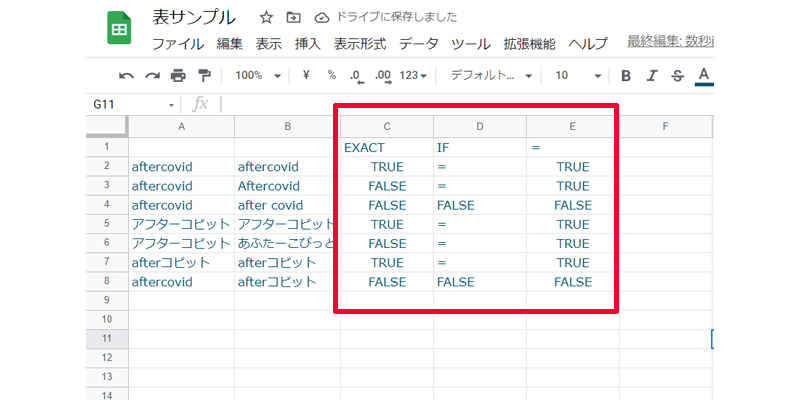
「IF関数」と「=」は大文字と小文字を区別しないどころか、カタカナとひらがなでも区別しません。(但しスペースとアルファベットとかなの組み合わせは「FALSE」になります。)
このように、完全一致を検証するときは、「EXACT関数」を大文字や小文字を区別しない場合やカタカナとひらがなを区別しない一致を検証するときは、「IF関数」、または「=」を使うようにしてください。
FIND関数 & SEARCH関数
基本的な使い方
構文=FIND(検索文字列, 検索対象のテキスト, [開始位置])
構文=SEARCH(検索文字列, 検索対象のテキスト, [開始位置])
大文字小文字を区別して、特定の文字列がテキスト内で最初に現れる位置を返します。
大文字小文字を区別せずに、特定の文字列がテキスト内で最初に現れる位置を返します。
全く同じ説明が書かれているようですが、違いが1点あります。それは大文字小文字を区別するかどうかの違いです。区別するのが「FIND関数」で、区別しないのが「SEARCH関数」になります。実際にどのように使うかは以下で詳しくご説明させて頂きます。
実際の使い方
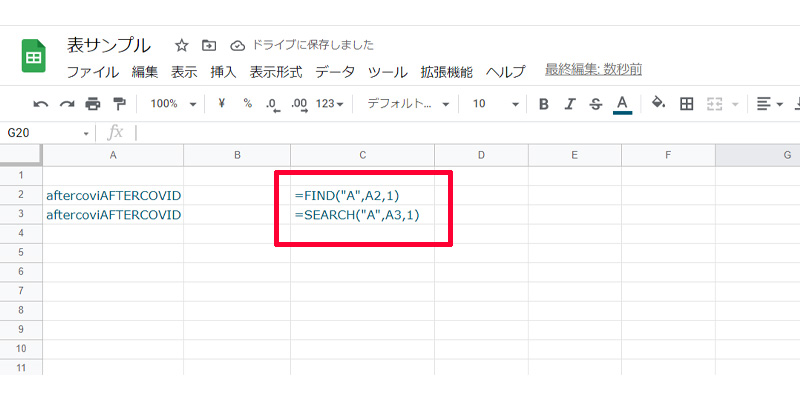
「aftercoviAFTERCOVID」と書かれた文字から、「A」の位置が何番目にあるのか調べてみましょう。数式は以下になります。
- FIND関数:=FIND(“A”,A2,1)
- SEARCH関数:=SEARCH(“A”,A3,1)
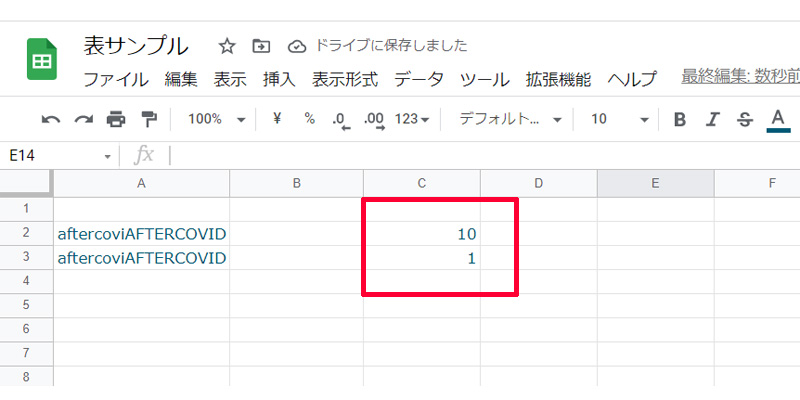
「FIND関数」では、大文字と小文字を区別しますので、大文字の「A」があるのは、10番目になります。「SEARCH関数」では、大文字と小文字を区別しませんので、1番目と表示されます。これらの関数は、実際に使用する時は、他の関数と組み合わせて利用されることが多いです。
LEN関数
基本的な使い方
構文=LEN(テキスト)
文字列の長さを返します。
説明を読んだ通りの機能です。文字列の長さを返します。実際にどのように使うかは以下で詳しくご説明させて頂きます。
実際の使い方
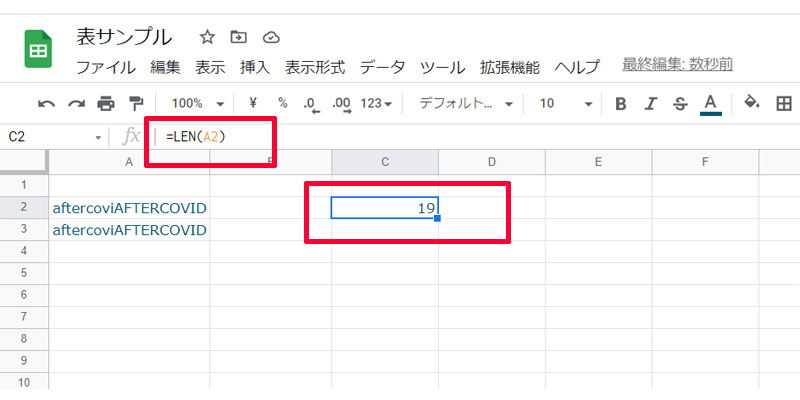
セルA2の文字列を数えます。数式は以下になります。
=LEN(A2)
SPLIT関数 & JOIN関数
基本的な使い方
構文=SPLIT(テキスト, 区切り文字, [各文字での分割], [空のテキストを削除])
構文=JOIN(区切り文字, 値または配列1, [値または配列2, …])
指定した文字または文字列の前後でテキストを分割し、各部分を同じ行の別のセルに表示します。
出典:Google ドキュメント エディタ ヘルプ SPLIT
指定した区切り文字を使用して、1 つ以上の 1 次元配列の要素を結合します。
少し分かりにくい内容ですが、とても簡単に言うと、「SPLIT関数」は、1つのセルに書かれたテキストを分割し、「JOIN関数」は2つ以上のセルに分割されているテキストを結合させます。実際にどのように使うかは以下で詳しくご説明させて頂きます。
実際の使い方
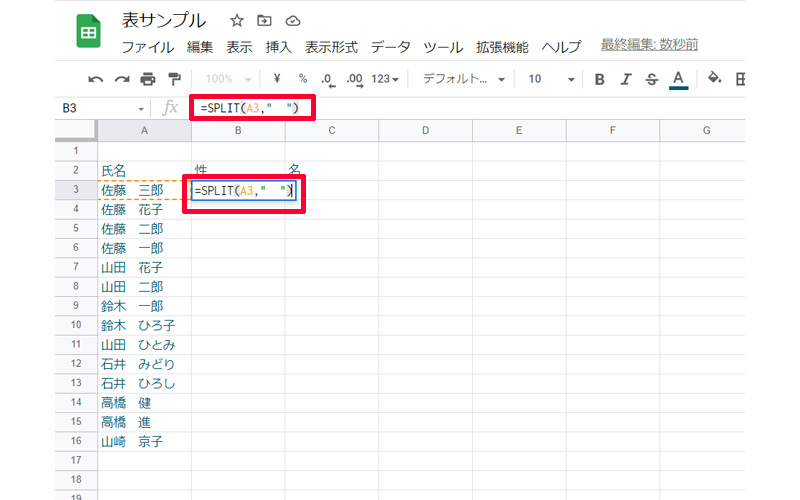
列Aにある氏名を、性と名に文化します。数式は以下になります。
=SPLIT(A3,” ”)
「A3」で分割するセルを指定して、「” ”」でどこで区切るかを指定しています。なお、A列にある氏名は、性と名の間には「全角のスペース」が入力されていますので、「” ”」の間も全角スペースを入力しています。半角スペースで入力されている場合は、半角スペースを入力してください。
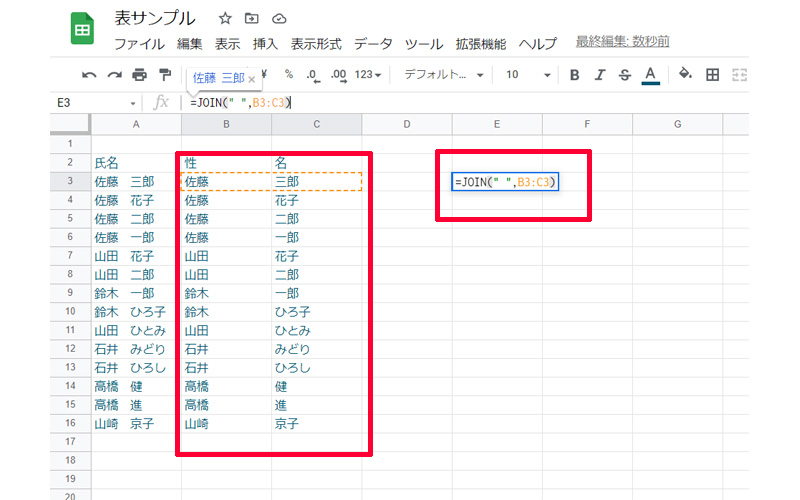
B列とC列に性と名が分割されて入力されました。続いてC列の性とD列の名を、「JOIN関数」を使って結合させます。数式は以下になります。
=JOIN(” “,B3:C3)
「” “」は半角スペースを空けています。
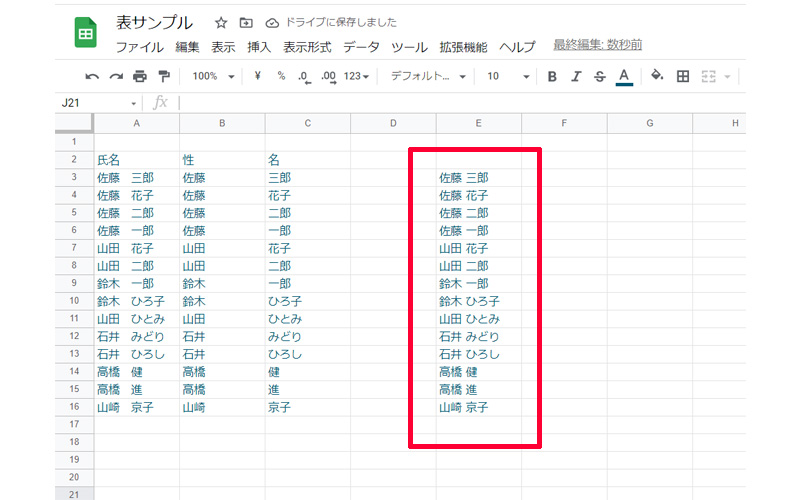
性と名が、半角スペースを空けて結合されました。JOIN関数の詳しい使い方や、文字列を結合する関数については、以下の記事で詳しくご紹介させて頂いております。

MID関数
基本的な使い方
構文=MID(文字列, 開始位置, セグメントの長さ)
文字列のセグメントを返します。
説明は少し分かりにくいですが、簡単に言うと、「セルの途中から文字を抜き出す」ことになります。実際にどのように使うかは以下で詳しくご説明させて頂きます。
実際の使い方
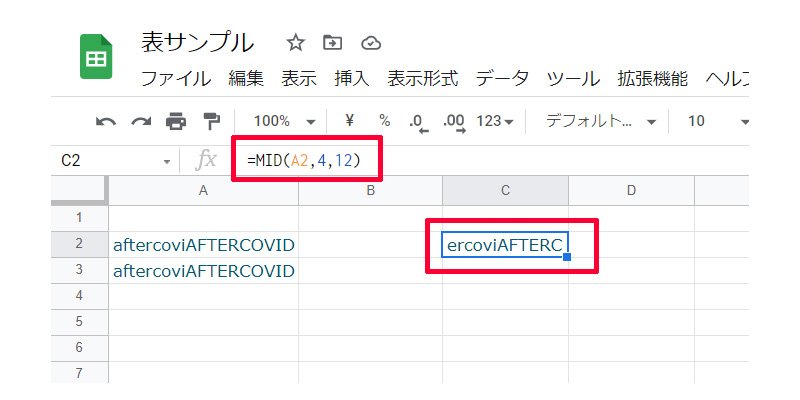
セルA2のテキストから、4番目から12文字のテキストを抜き出します。以下数式になります。
=MID(A2,4,12)
同様の関数として以下のものがあります。
- RIGHT関数:指定した数値を、右からカウントします。
- LEFT関数:指定した数値を、左からカウントします。
使い方は「MID関数」と同じ感じですが、引数は1つになります。
「=RIGHT(A2,4) 」
SUBSTITUTE関数
基本的な使い方
構文=SUBSTITUTE(text_to_search, search_for, replace_with, [occurrence_number])
文字列内の既存のテキストを新しいテキストに置き換えます。
構文は長く書かれているので難しそうですが、説明にある通り、テキストを他のテキストと置き換える関数になります。実際にどのように使うかは以下で詳しくご説明させて頂きます。
実際の使い方
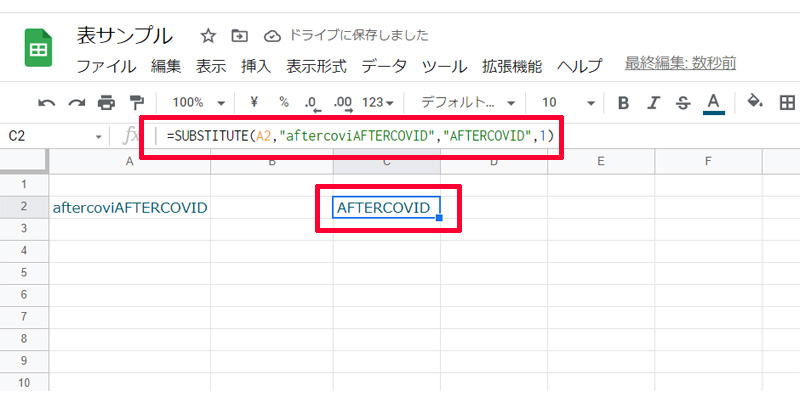
セルA2にある「aftercoviAFTERCOVID」というテキストを、「AFTERCOVID」に置き換えます。数式は以下になります。
=SUBSTITUTE(A2,”aftercoviAFTERCOVID”,”AFTERCOVID”,1)
「aftercoviAFTERCOVID」 の全文を変更しましたが、一部だけでも変更可能です。最後の「1」は省略しても問題ありません。また、同じ結果を得るのに全文を選択して、新しいテキストを入力しなくても、必要なテキストだけ抽出することも可能です。
=SUBSTITUTE(A2,”aftercovi”,””)
「aftercoviAFTERCOVID」 から「aftercovi」だけを取り除いて、「AFTERCOVID」だけを表示させています。
置き換え機能との違い
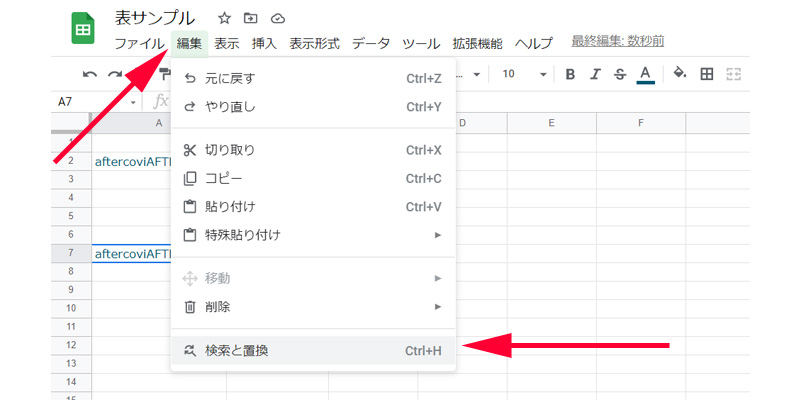
Googleスプレッドシートには、同様の機能に、「検索と置換」があります。セルを選択して、メニューバーから「編集」→「検索と置換」をクリックします。(ショートカットキー、「CTRL + H」でも表示されます)
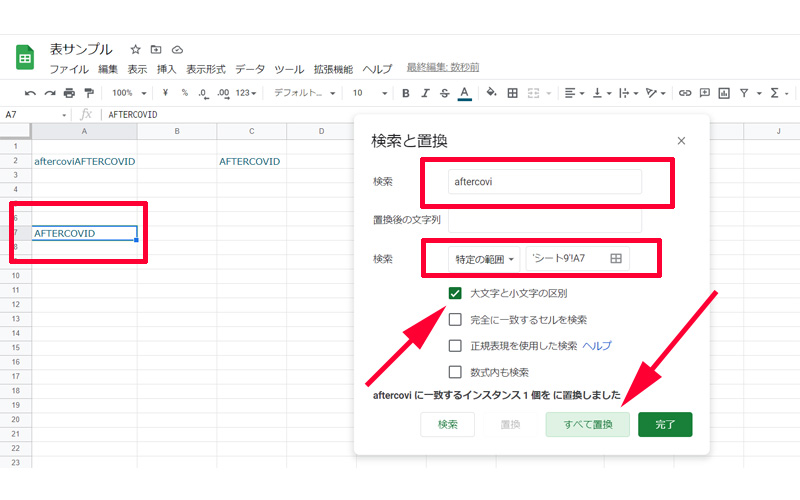
「検索と置換」の編集画面が表示されますので、検索に「aftercovi」と入力し、検索の範囲を「A7」に指定、「大文字と小文字の区別」にチェックを入れて、一番下の「すべて置換」をクリックします。「aftercoviAFTERCOVID」 から「aftercovi」だけを取り除いてた、「AFTERCOVID」だけが表示されています。
「SUBSTIUTE関数」を使うか、「検索と置換」のどちらを使うかは、元のデータの扱いによって決まります。「SUBSTIUTE関数」であれば、元のデータは残りますが、「検索と置換」を使うと元のデータは消えてしまいます。どちらを使うかはご利用の環境によって選択してください。
マスターが教える「テキスト関数」活用のツボ
- 「半角スペース」と「全角スペース」の違いに注意!: SPLITやJOINで区切り文字を指定するとき、スペースの種類を間違えると正しく動きません。見た目では分かりにくいので、うまくいかない時はまずここを疑いましょう。
- 数式の結果を「値」として確定させる: 関数の結果を別の場所にコピペしたいときは、『形式を選択して貼り付け』→『値のみ貼り付け』を使いましょう。これをしないと、元データを消したときにエラーになってしまいます。
- 大文字・小文字を揃える関数もセットで: 検索の前に、UPPER(すべて大文字に)や LOWER(すべて小文字に)を使ってデータの表記を揃えておくと、検索の精度がグッと上がりますよ。
まとめ
お疲れ様でした!文字操作のストレスを劇的に減らすテキスト関数の世界はいかがでしたか?
- 厳密に同じか調べるなら、EXACT
- 文字がどこにあるか探すなら、FIND / SEARCH
- 区切り文字で分ける・つなぐなら、SPLIT / JOIN
- 好きな場所から抜き出すなら、MID / LEFT / RIGHT
- 別の文字にサクッと入れ替えるなら、SUBSTITUTE
最初は「難しそう」と感じるかもしれませんが、まずは一つの数式をコピーして使ってみるだけでOKです。数式が動いた瞬間の「おぉ!」という感動が、あなたのスキルアップの第一歩になります。
これらの関数を組み合わせることで、スプレッドシートでの表現力は無限に広がります。ぜひ、あなたの日常業務という「パズル」を、これらの関数で解いてみてくださいね!
今回も最後までお読みいただき、ありがとうございました。


コメント