
「Googleスプレッドシートのピボットテーブルって、何だか難しそう…」
「データ分析に役立つって聞くけど、どうやって使えばいいか分からない…」
そんな悩みをお持ちのあなたへ。
この記事では、Googleスプレッドシートのピボットテーブルの使い方を徹底解説します。
データの準備から作成、集計、分析、そして応用テクニックまで、これ1つでピボットテーブルをマスターできる完全ガイドです。
この記事を読めば、データ分析スキルが格段に向上し、業務効率も大幅アップ!
ぜひ最後まで読んで、ピボットテーブルの便利さを実感してください。
データの準備等大変に思われるかもしれませんが、一つ一つ記事のとおりに手順を進めていけば、どなたでもピボットテーブルを使いこなせるようになります。ぜひ一緒に学んでいきましょう。
もし、少し難しいと思われた場合は以下の記事をご参照ください。
シンプルな表でピボットテーブルを使う方法をご紹介させて頂いております。
データを準備する
今回使用するデータを準備します。
お手持ちのデータがあればそちらをご使用頂いても問題ありません。
当記事と全く同じデータを使用したい場合は以下の手順で進めてください。
Kaggle へアクセス
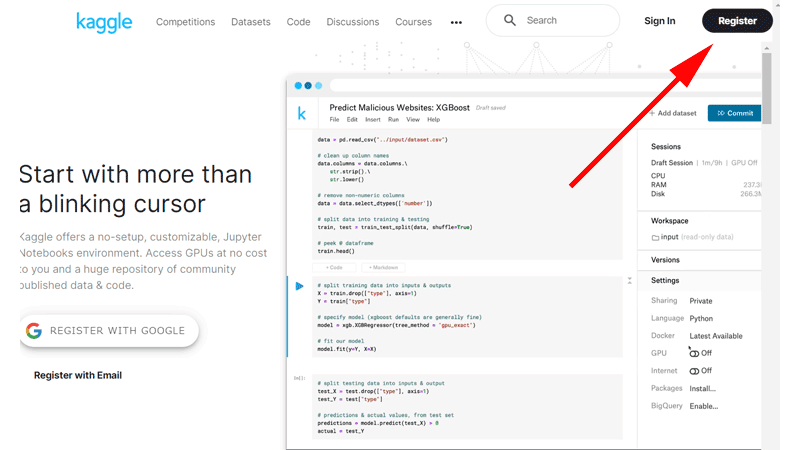
まずは、「kaggle」というサイトにアクセスします。
「kaggle」を知らない方もいらっしゃるかと思いますので、簡単に説明させて頂くと以下になります。
Kaggle(カグル)は企業や研究者がデータを投稿し、世界中の統計家やデータ分析家がその最適モデルを競い合う、予測モデリング及び分析手法関連プラットフォーム及びその運営会社である。
2017年にグーグルが買収して、現在はグーグル傘下の企業ですので安心して利用することが出来ると思います。
ユーザー登録
「kaggle」を利用するには、ユーザー登録が必要になります。
トップページの右上にある「Register」をクリックします。
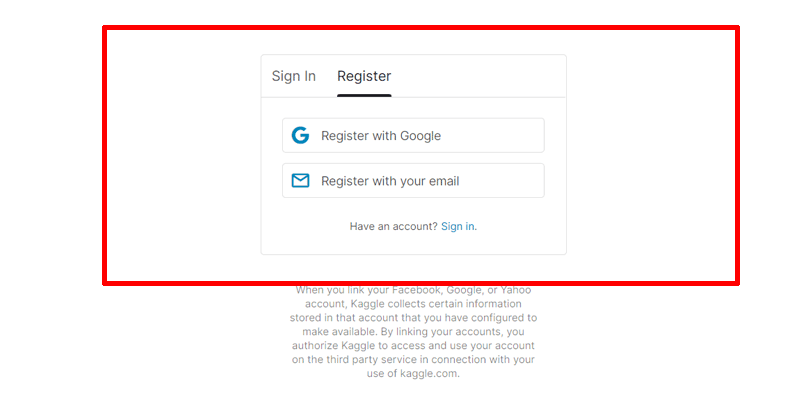
「Googleアカウント」または「email」で登録することが出来ます。
手順は簡単ですので、お好きな方で登録しておいてください。
データを探す
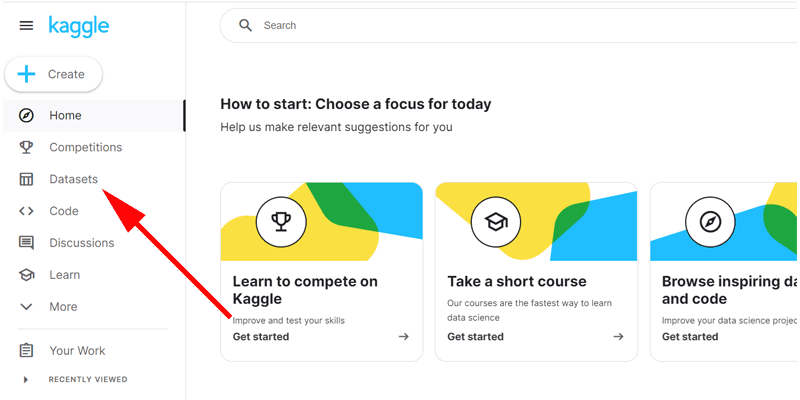
左側にあるメニューから「Datasets」をクリックします。
画面上の「Search」と書かれた検索ボックスからも直接検索することが出来ますが、初めての方は、手順通りに検索してみてください。
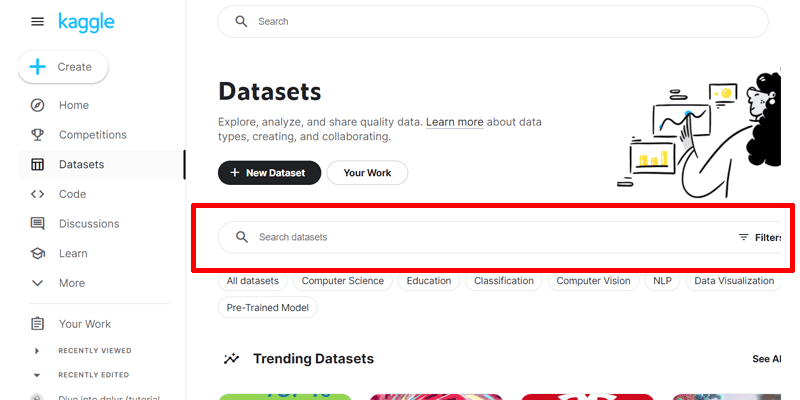
「Datasets」の画面が表示されますので、ボックス内にキーワードを入力して検索します。
ここでは、「Superstore Sales Dataset」と入力します。
条件を付けて検索する場合は、検索ボックスの右側にある、「Filter」をクリックします。
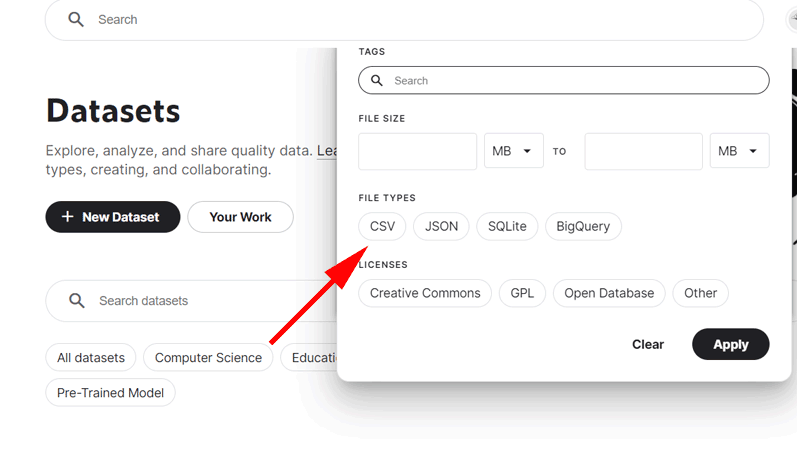
ファイルサイズやファイルタイプなどを指定することが出来ます。
スプレッドシートで作業する場合は、「File Types」の部分で「CSV」を選択するようにしてください。
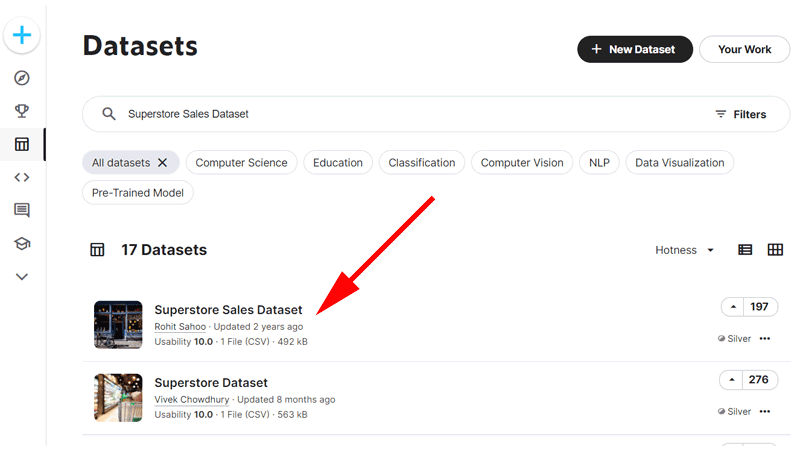
一番上に「Superstore Sales Dataset」と表示されていますので、こちらをクリックします。
ダウンロードする
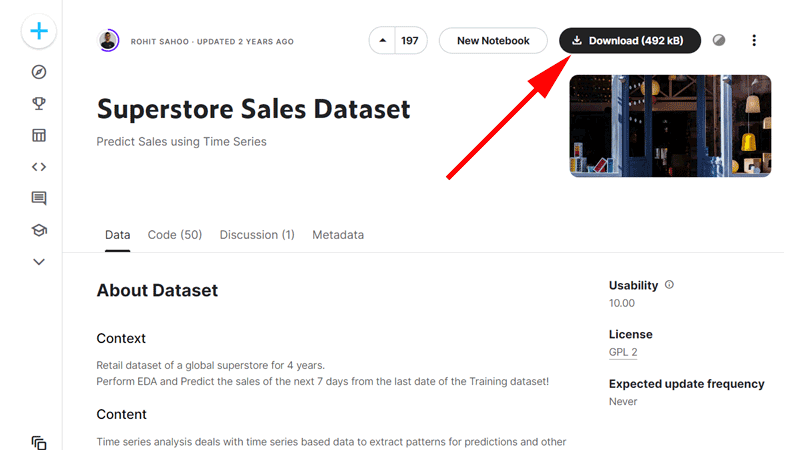
「Superstore Sales Dataset」のページが表示されました。
ここではこのデータを使用しますので、画面右上にあるダウンロードボタンをクリックします。
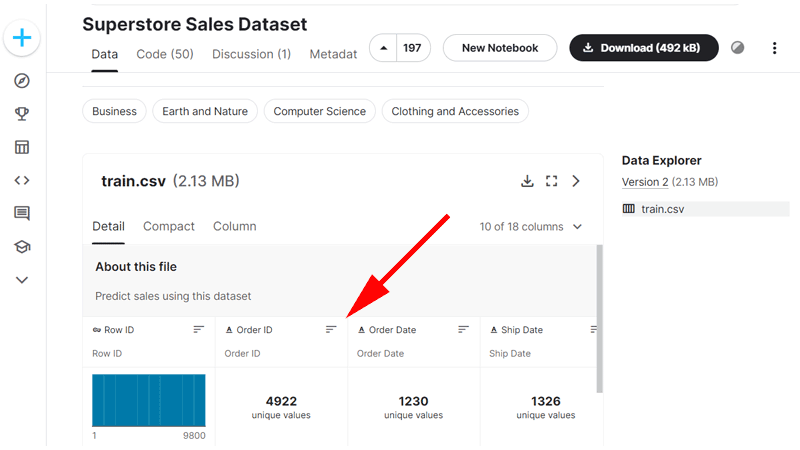
なお、画面を下にスクロールすると、ファイルの中身を確認することが出来ます。
矢印の先の3本線のボタンをクリックするとデータを並べ替えたりすることが出来ます。
データベースが自分が必要とするものなのかどうか、ダウンロードする前に確認することが出来ます。
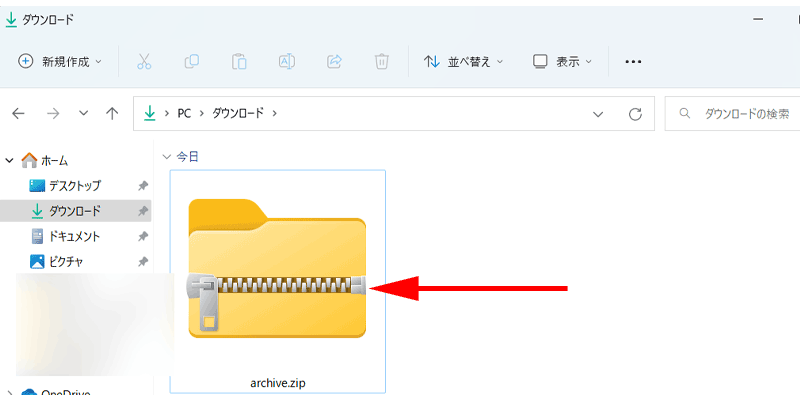
パソコンのダウンロードフォルダに、「archive」という圧縮フォルダがダウンロードされていますので、解凍してから分かりやすい場所に保存しておいてください。
圧縮フォルダの解凍方法が分からない方、または解凍するソフトをお持ちでない場合は、無料の解凍ソフトをダウンロードして解凍してください。
「窓の杜」等で、「無料解凍ソフト」で検索すれば多数候補が出てきます。
Windowsをお使いの方は、ダウンロードフォルダにあるファイルをダブルクリックするとファイルが表示されますので、そのままデスクトップなどへ移動すればすぐに利用することが出来ます。
データをスプレッドシートにインポートする
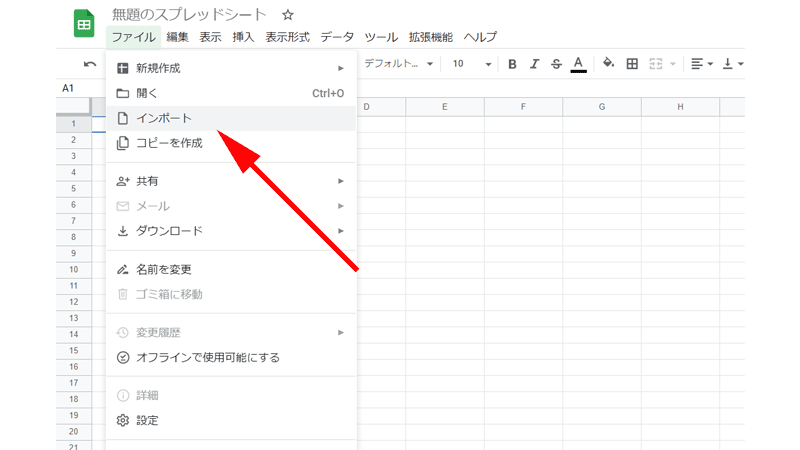
「ファイル」から「インポート」をクリックします。
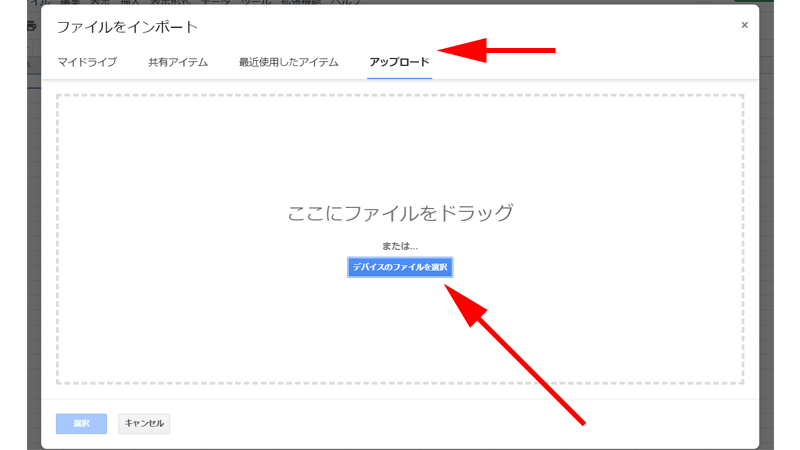
画面上の項目から「アップロード」を選択して、画面中央にある、「デバイスのファイルを選択」をクリックします。
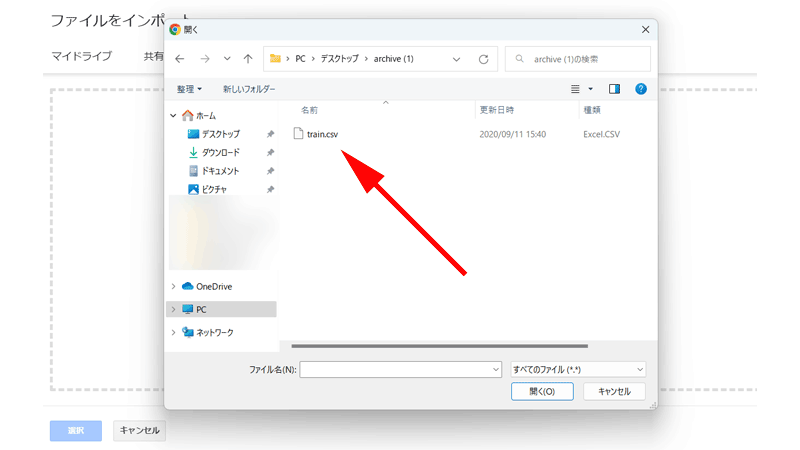
解答した「train」ファイルを選択して「開く」ボタンをクリックするか、ファイルをダブルクリックします。
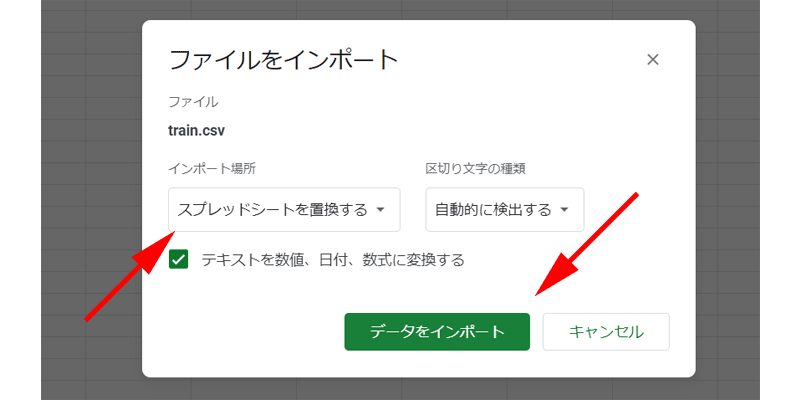
「ファイルをインポート」画面が表示されますので、「インポート場所」を選択します。
空白のファイルから操作を行った場合は、「スプレッドシートを置換する」を選択して、「データをインポート」をクリックします。
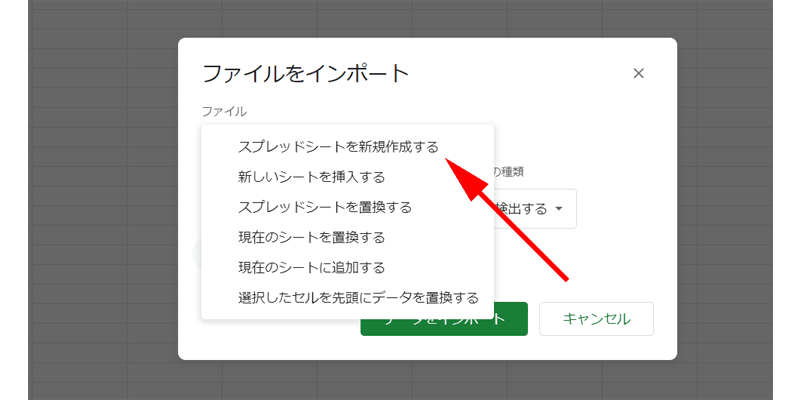
既存のファイルを開いた状態でデータのアップロードを行った場合は、「インポート場所」で「スプレッドシートを新規作成する」を選択して、「データをインポート」をクリックします。
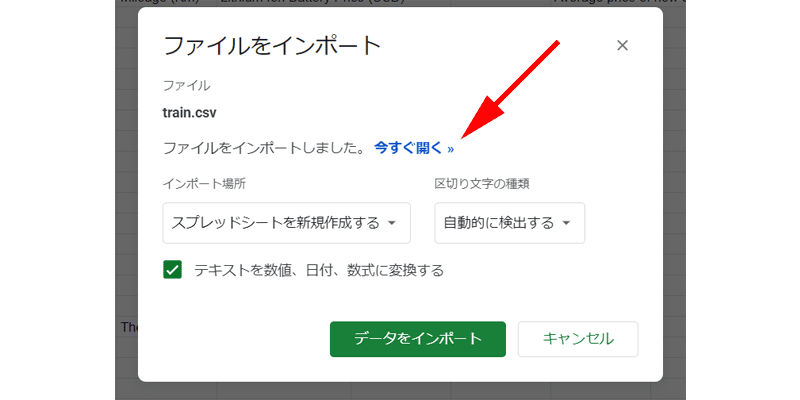
インポートが完了したら「今すぐ開く」をクリックします。
空白ファイルからインポートされた方は、この画面は表示されません。
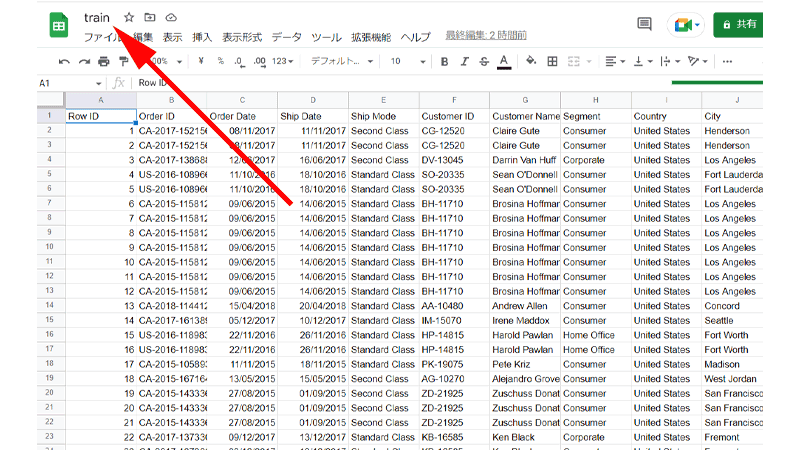
ファイルが表示されたら、データのインポートは完了です。
ファイルに分かりやすい名前を付けておきましょう。
ピボットテーブルの操作
ピボットテーブルの作成
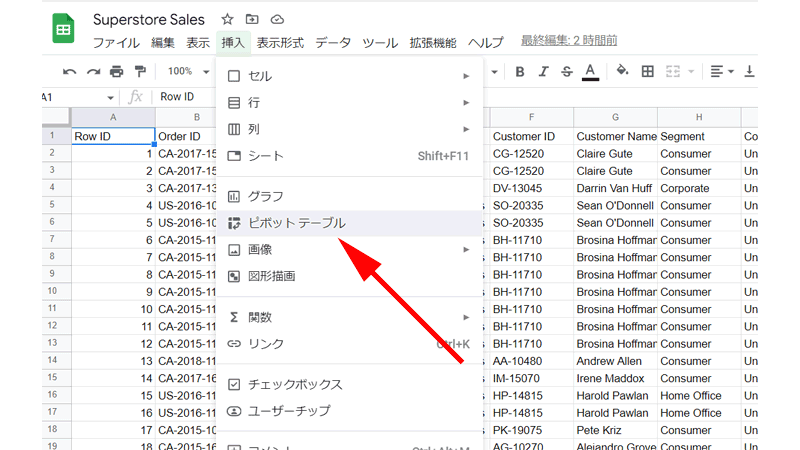
表の中の任意のセルをクリックします。
メニューから「挿入」→「ピボットテーブル」をクリックします。
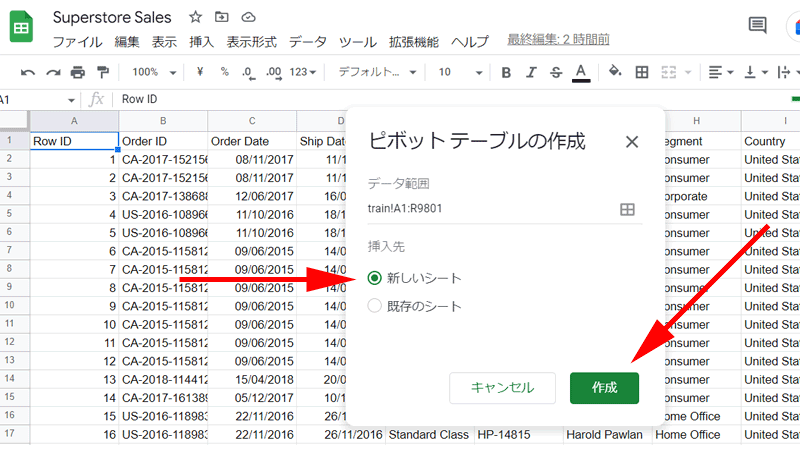
「ピボットテーブルの作成」ウィンドウが表示されますので、「データ範囲」と「挿入先」を指定します。
通常「データ範囲」は自動で入力されていると思いますが、範囲の指定が必要な場合は範囲を指定し直してください。
「挿入先」に関しては、「新しいシート」を選択するようにしてください。
小さなデータの時は「既存のシート」でも良いですが、大きなデータを扱う時は必ず「新しいシート」を選ぶようにしてください。
元のデータを保護する意味でも「新しいシート」を使用するほうが良いでしょう。
「データ範囲」と「挿入先」を指定したら、「作成」ボタンをクリックします。
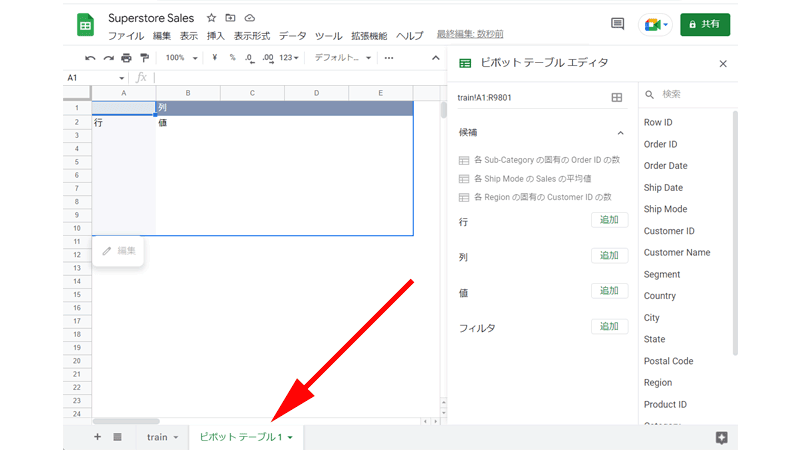
「ピボットテーブル」が表示されました。
まずはシートの名前を分かりやすい名前に変更します。
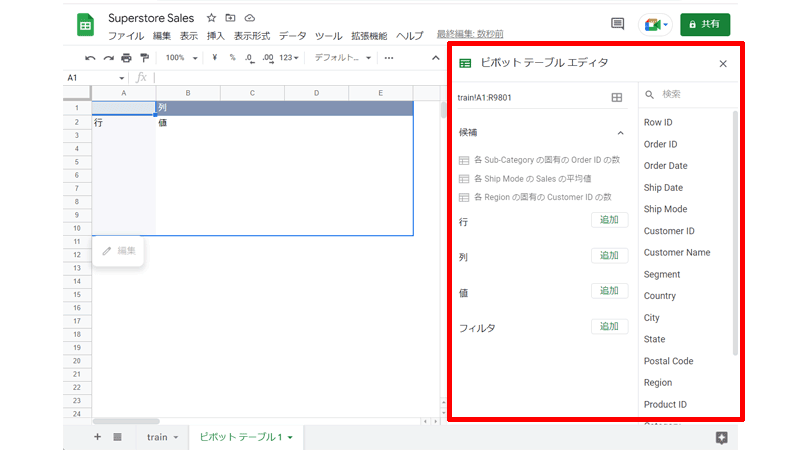
画面右側には、「ピボットテーブルエディタ」が表示されています。
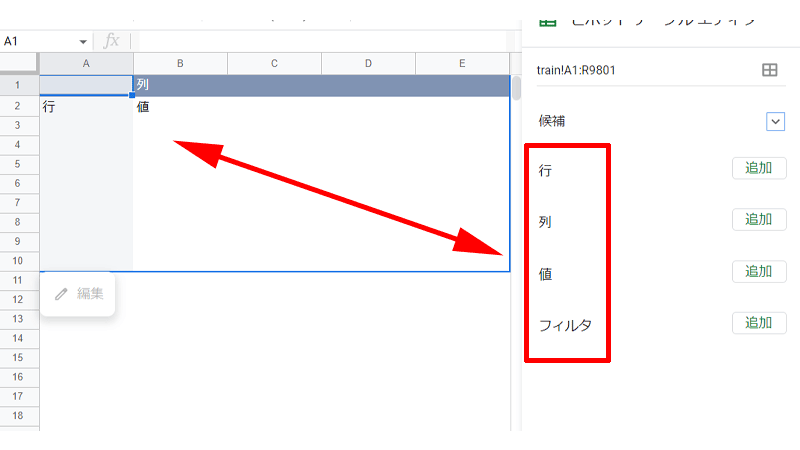
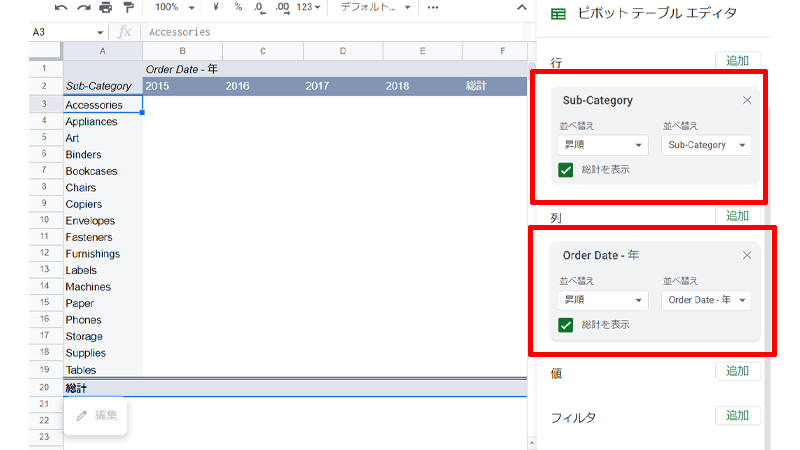
「ピボットテーブル」は「行」、「列」、「値」、「フィルタ」の4つの要素から構成されています。
「行」、「列」、「値」はシートに表示されている場所に対応しています。
- 行:データを横方向に整理します。
- 列:データを縦方向に整理します。
- 値:データの計算に使われます。
- フィルタ:通常の表で操作するのと同じように、条件を付けてフィルタを適用させます。
行を追加する
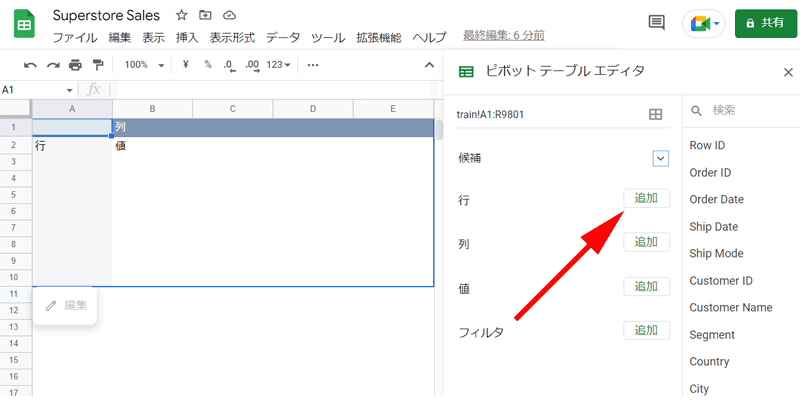
「ピボットテーブル」を作成するには、最初に「行」を指定します。
ここでは「行」を「オーダー日(Order Date)」で並び替えていきます。
「行」の隣にある「追加」をクリックします。
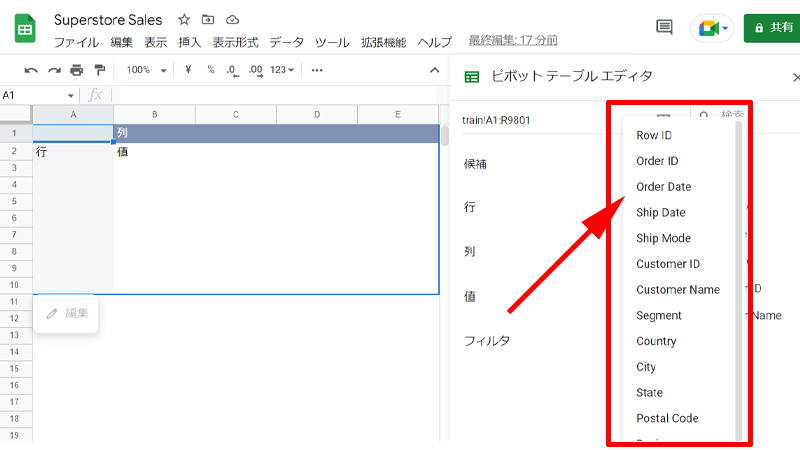
表の「属性」が表示されますので、「Order Date」をクリックします。
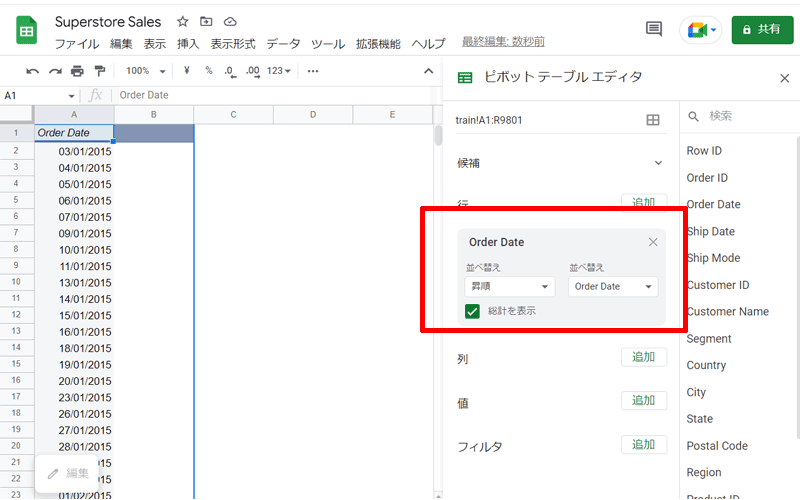
「A列」に「Order Date」が「昇順」に並び替えられました。
もし「降順」で並び替えたい時は、「並べ替え」の所をクリックして「降順」を選択してください。
なお、ここでは「Order Date」を「追加」ボタンから選択しましたが、画面の一番右側にある「属性」の中から各要素にドラッグアンドドロップをしても同じ結果を得ることが出来ます。
日付が「03/01/2015」のように、すべて「日」単位で表示されているので、「年」単位に絞って表示させてみましょう。
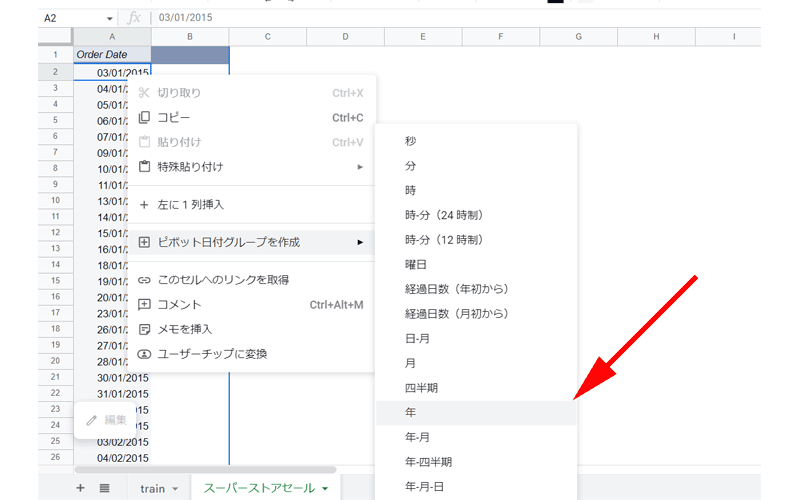
「A列」の任意の場所をクリックして、右クリックします。
メニューからが表示されますので、「ピボットテーブル日付グループを作成」→「年」をクリックします。
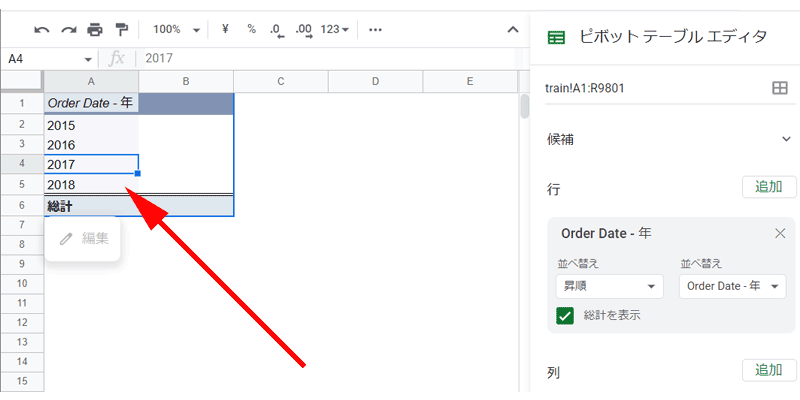
「Order Date」が「年」ごとにまとまって表示されました。
ここでは「行」を短くするために、「年」を選択しましたが、「月」、「年-月」、「四半期」など様々な期間を選択することが出来ます。
値を追加する
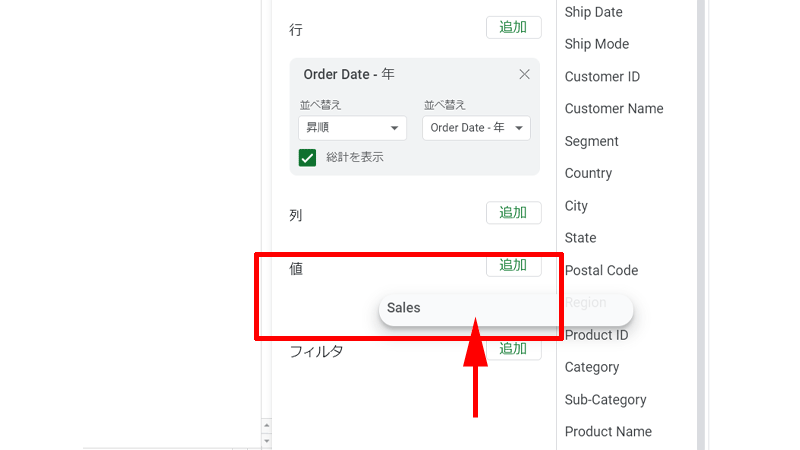
次に「値」に「Sales」を追加してみましょう。
今回は、右側にある「属性」の中から「Sales」をドラッグアンドドロップで追加してみます。
「値」の下辺りでドロップすれば、追加されます。
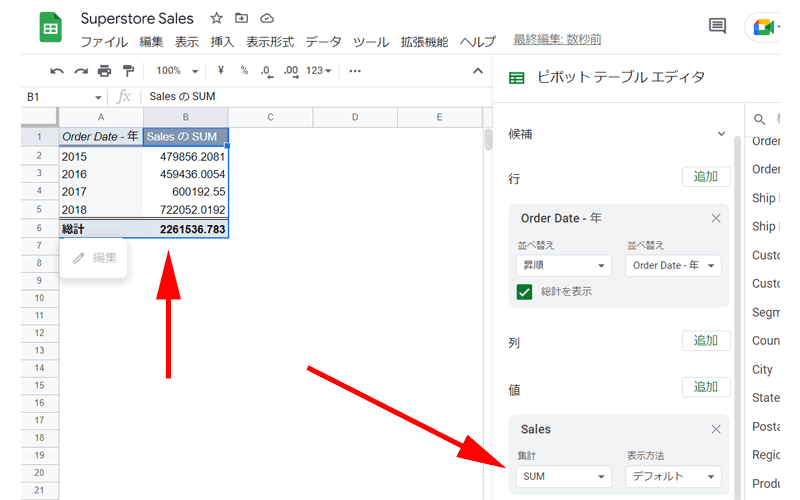
テーブルに、各年の売上の合計金額が表示されました。
「Sales」の「集計」部分には「SUM」が自動で適用されているので、特に操作をしなくても、テーブルには合計金額が表示されています。
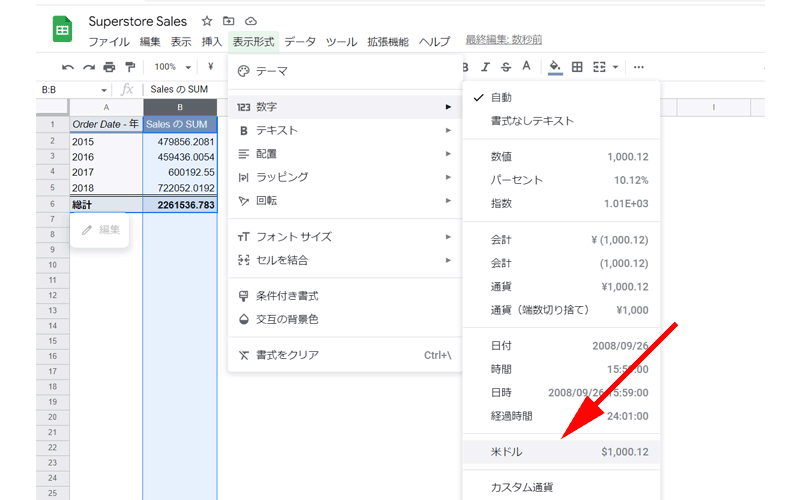
「値」の表示が分かりやすいように、米ドル表示に変更します。
「B列」を選択して、メニューから「表示形式」→「数字」→「米ドル」をクリックします。
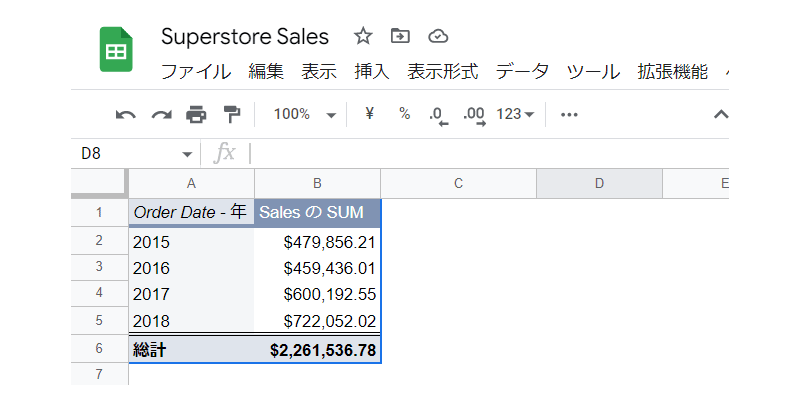
ドル表示に変更されました。
2016年は少し売上が下がりましたが、2017年、2018年と売上が順調に増えているのが分かります。
続いて各年の平均売上を追加してみましょう。
手順は先程と同じになります。
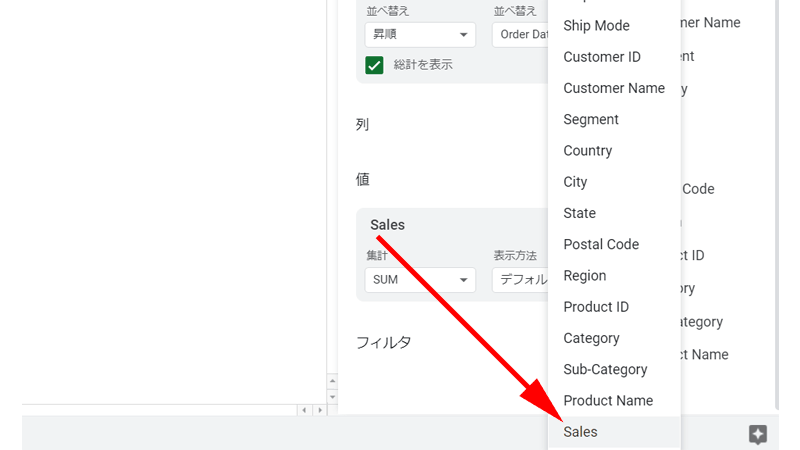
「値」の「追加」ボタンをクリックして、「Sales」をクリックします。
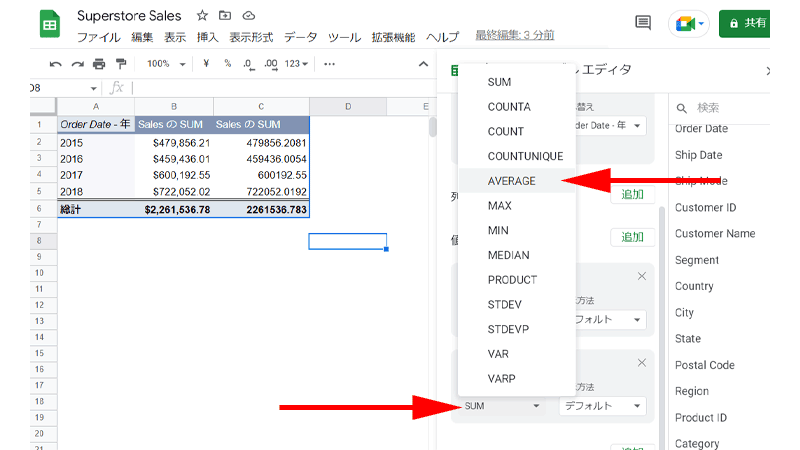
追加した「Sales」の「集計」部分をクリックして、「AVERAGE」をクリックします。
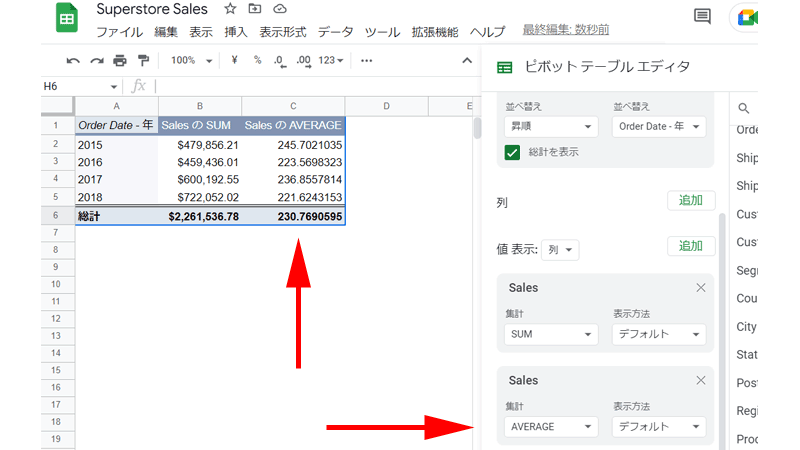
「C列」に平均売上高が表示されました。
こちらも表示をドルに変更しておきましょう。
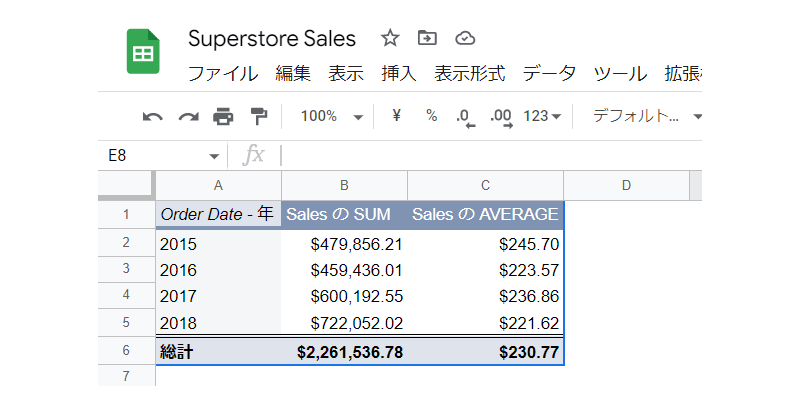
全体の売上は年ごとに上昇傾向ですが、平均売上高が下がっているのが分かります。
続いて、各年の注文数を表示してみましょう。
どの項目から注文数を計算するか分かりにくいですが、表を見ると、「Order ID」が良さそうです。
早速「値」に「Order ID」を追加してみましょう。
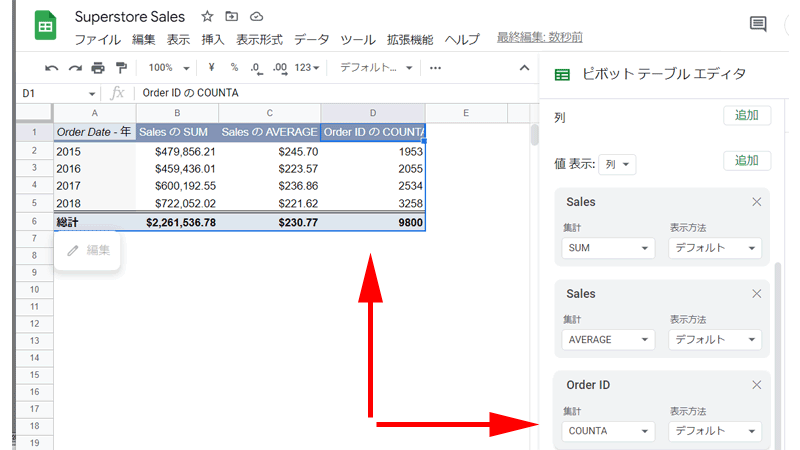
「Order ID」を追加すると、「集計」は自動的に「COUNTA」が適用されています。
表には、各年のオーダーIDの数が表示されていますが、「総計」が「9800」と表示されています。
これは、表の「行」の数と同じなので、その年のオーダーIDをただ単に数えただけになっています。
つまり同じオーダーIDも一つ一つ数えてしまっていますので、正しいオーダー数が表示されていません。
そこでここでは、集計の「COUNTA」を「COUNTUNIQUE」に変更してみます。
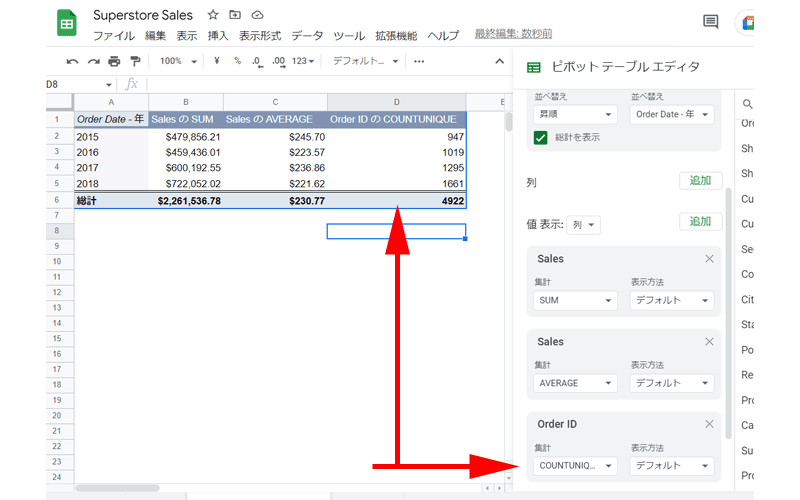
「Order ID」の各年の数値が変更されました。
「総計」も「4922」と表示されていますので、正しいオーダー数が表示されているのがわかると思います。
集計の関数を「COUNTUNIQUE」に変更したことで、何が起きたかというと、複数ある同じ「Order ID」を一つとして計算したということになります。
つまり、「COUNTUNIQUE」は重複を除外してデータをカウントしてくれる関数だということになります。
COUNTA関数:データセット内の値の個数を返します。
COUNTUNIQUE関数:指定した値や範囲のリストから、一意の値(重複を除外した)の個数をカウントします。
複数のピボットテーブルを作成する
ピボットテーブルを移動する
先程ピボットテーブルを作成しましたが、同じシートにもう一つピボットテーブルを作成してみましょう。
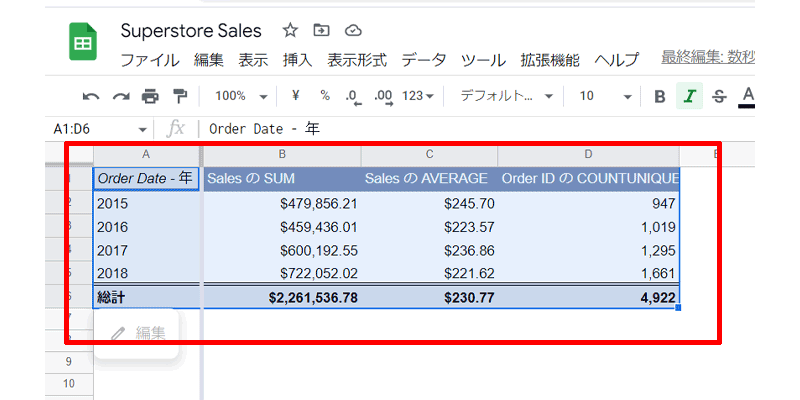
先程作成したピボットテーブル全体をコピーします。
「O列」以降の場所にペーストしておきます。
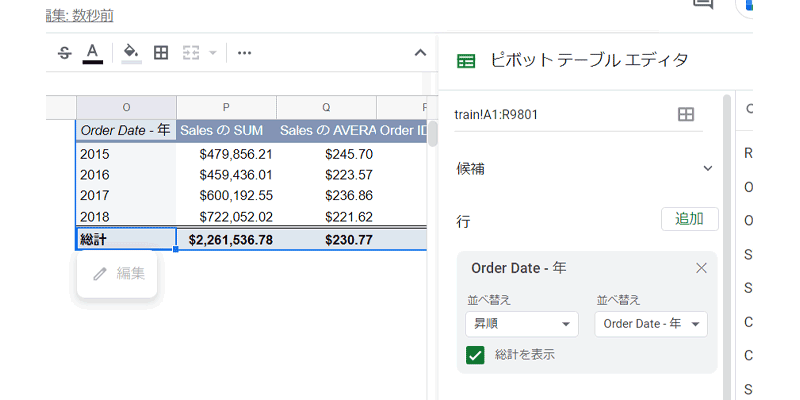
このような感じでペーストしておいてください。
コピーアンドペーストしたピボットテーブルも、「編集」ボタンをクリックすれば、ピボットテーブルエディタが表示されますので、編集することが可能です。
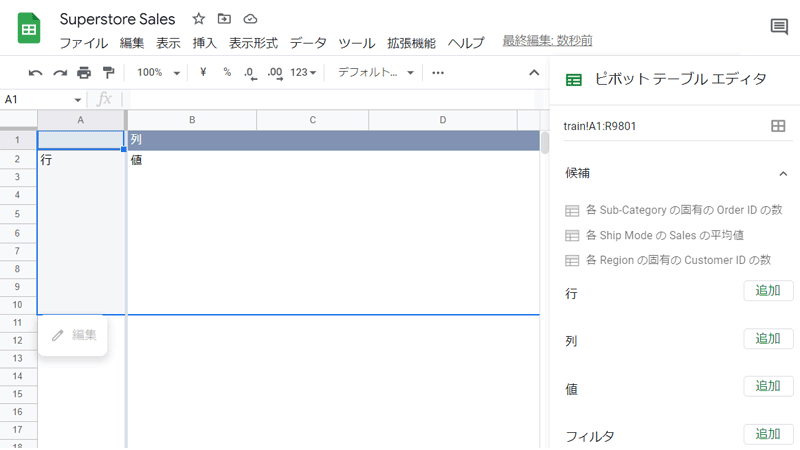
最初のピボットテーブルに戻って、「行」と「値」に追加した項目はすべて削除します。
これで最初の状態に戻りましたので、再びテーブルを作成していきましょう。
今度のテーブルでは「州」ごとの売上を、各年度ごとに比較してみます。
行を追加する
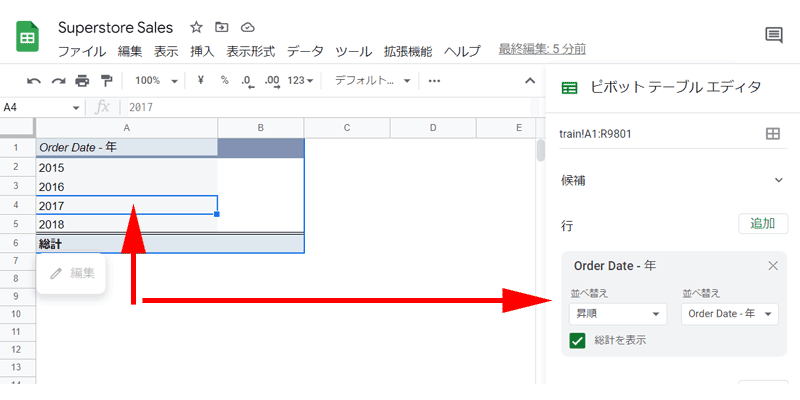
まずは「行」に「Order Date」追加して、「年」表示にさせます。
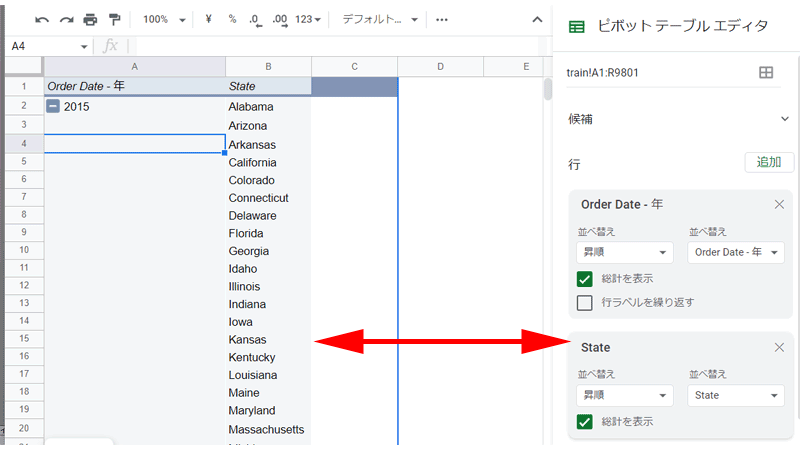
次に、「行」に、「State」を追加して、「州」を表示させます。
列を追加する
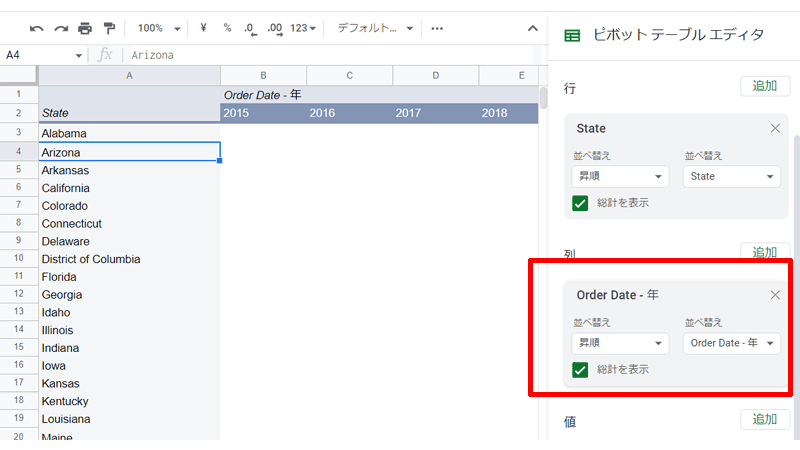
「行」にあった「Order Date」を「列」に移動させます。
表が見やすくなったと思います。
「Order Date」を直接「列」に追加すれば、良いのではないかと思われるかもしれません。
しかし「列」に直接「Order Date」を追加するとエラーが表示されてしまいます。
これは、「列」の長さが長くなりすぎてしまうために起こるエラーです。
そのため今回の手順のように、一度「行」に追加して長さを調節した後に「列」に移動させると問題なく表示されるようになります。
値を追加する
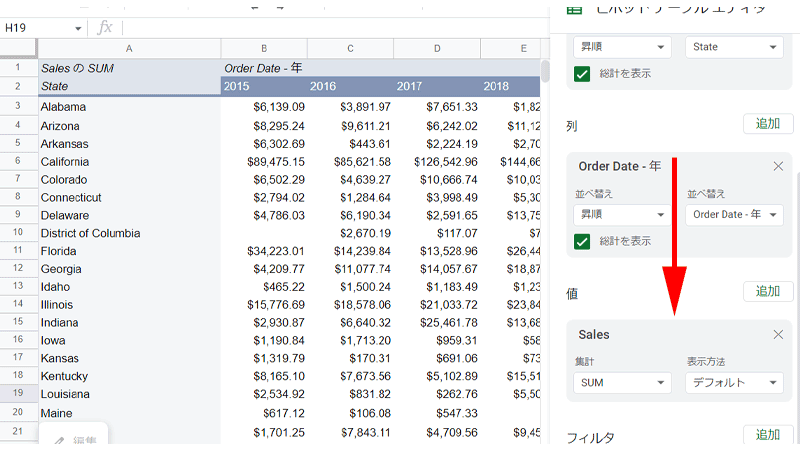
続いて「値」に「Sales」を追加します。
表には、各州の各年度の売上が表示されました。
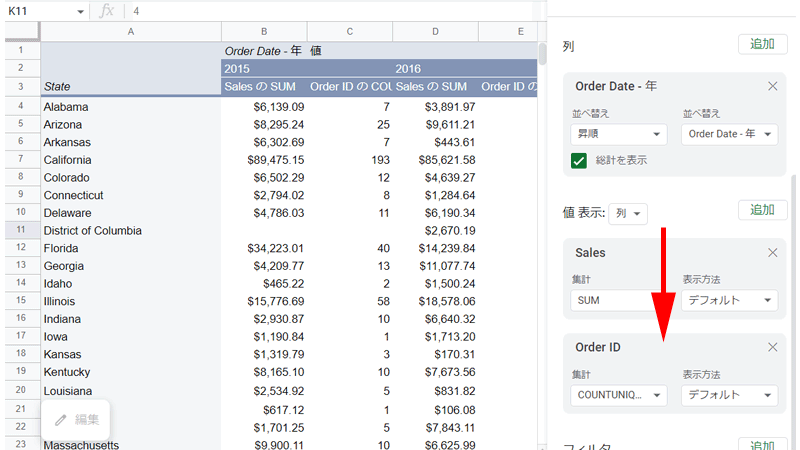
「値」に「Order ID」を追加して「注文数」を表示させます。
列を固定表示させる
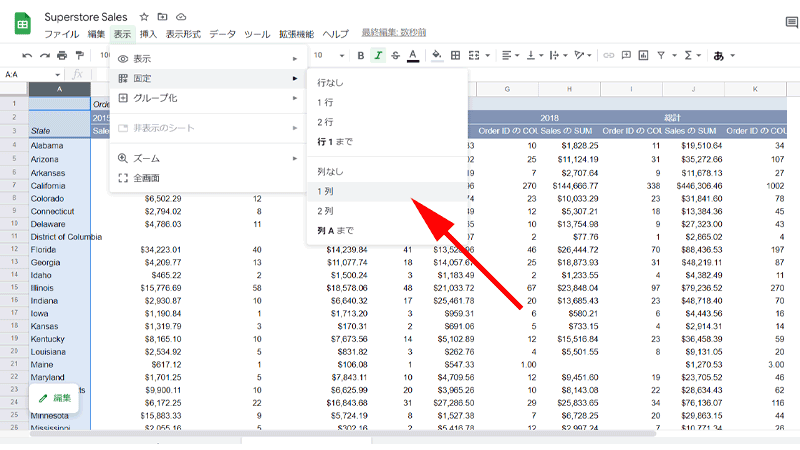
後ほど分析しやすいように、「A列」を固定表示にします。
メニューから「表示」→「固定」→「1列」を選択します。
これで、シートを動かしても、「A列」は常に固定された状態になります。
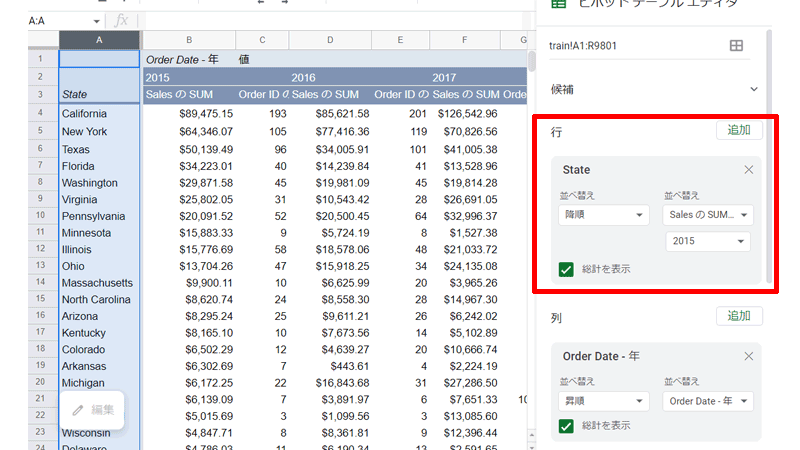
並び順を変更します。
「行」の「State」の「並べ替え」を「降順」に、右側の「並べ替え」は、「SalesのSUM」にして年度を「2015」にします。
これで、2015年の売上が多い順に「州」が並び替えられました。
平均売上高を計算する
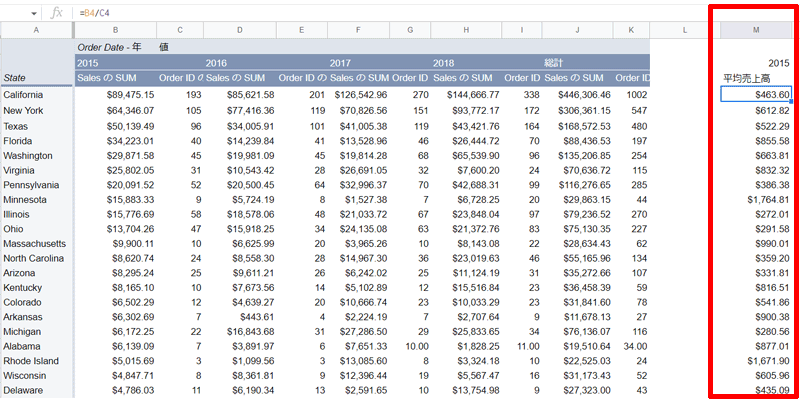
「M列」に「平均売上高」(1オーダーあたり)を挿入してみましょう。
ここは通常の数式で計算します。
セル「M4」に「=B4/C4」と入力すると、「California」の1オーダーあたりの平均売上高が表示されます。
あとは範囲内までペーストすれば、各州の1オーダあたりの平均売上高が表示されます。
考察
この表から色々なことがわかると思いますが、年間売上が最も多い「California」の平均売上高があまり高くないことがわかると思います。
また年間売上、上位10州の中では、「Minnesota」が「$1,764.81」と「California」の4倍近い金額になっています。
この理由は、どんな商品が売れているのかを調べたりすると何かしらの理由が見つかるかもしれません。
さらに各年度各州の平均売上高を見ていけば、この傾向が偶然なのか理由があるのかもわかるかもしれません。
このあたりの操作はここでは割愛させて頂きますが、ぜひピボットテーブルを操作してその理由を探してみてください。
複数のピボットテーブルのデータを使用する
割合を調べる
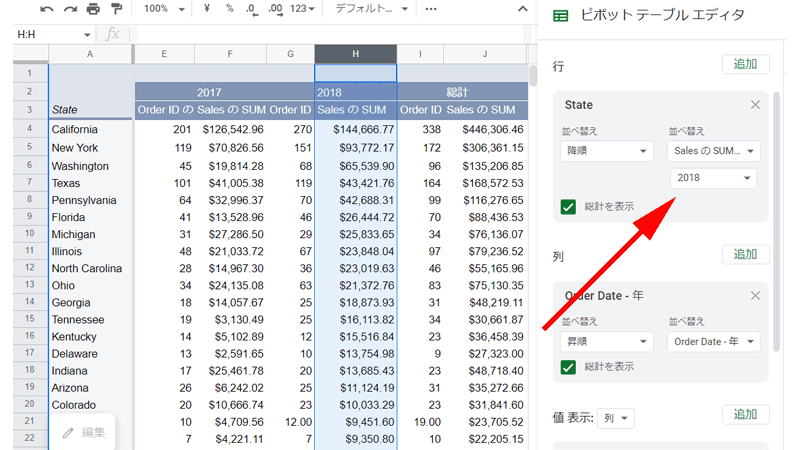
今度は2018年の各州の売上高が、総売上高の何%を占めているのか計算してみましょう。
まず最初に、「State」の右側の並べ替えを「2018」にします。
これで「A列」の「州」は、2018年の売上高順に並び替えられました。
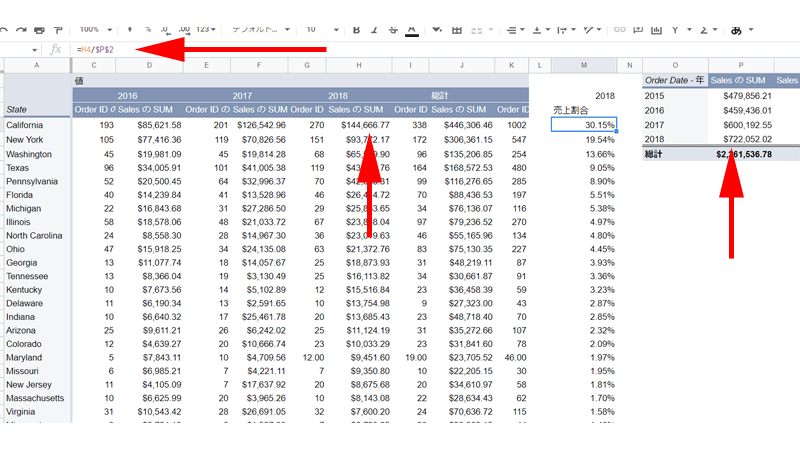
セル「M4」に、2018年度の総売上高に占める「California」の売上割合を計算します。
計算は通常の数式を使用します。
計算式は、「=H4/$P$2」と入力します。
「H4」はカリフォルニア州の売上高、「P2」は最初に作成したピボットテーブルにある2018年の総売上高になります。
式の中では、「P2」を「$」と一緒に記述しています。
これは、「絶対参照」と言われるもので、この方法で記述しないと数式を下にコピーアンドペーストした時に、総売上高のセルも一緒に下にずれてしまいますので注意してください。
セル内の数値は「%」で表示するとより分かりやすくなります。
考察
売上割合を見てみると、カリフォルニア州の売上が占める割合が「30%」と、かなり高いことが分かります。
さらに上位3つの州の割合を合計すると何と「63%」にもなります。
これは2018年に限ったことなのか、もともと同じような割合なのか調べてみる必要がありそうです。
各年度の割合を計算してぜひ比べて見てください。
また「Order ID」で「注文数」も集計していますので、こちらの割合を調べてみるのも良いかもしれません。
売上割合と比例しているのか、比例していないのかを確認したら、何故そうなったのか突き止めて見るのも良いかもしれません。
フィルタと計算フィールド
行と列を追加する
今度は、「商品」ごとの売上を見てみましょう。
基本的な手順は、先程作成した「州」ごとのテーブルと同じになります。
「行」に「Sub-Category」を追加します。
元のデータでは「Category」列もあるのですが、こちらは「Furniture」など大きな分類になっているので、ここには適していませんでした。
「列」には、「Order Date」を追加します。
「州テーブル」と同じように、一度「行に」挿入して表示を「年」に変更してから「列」に移動させてください。
値を追加する
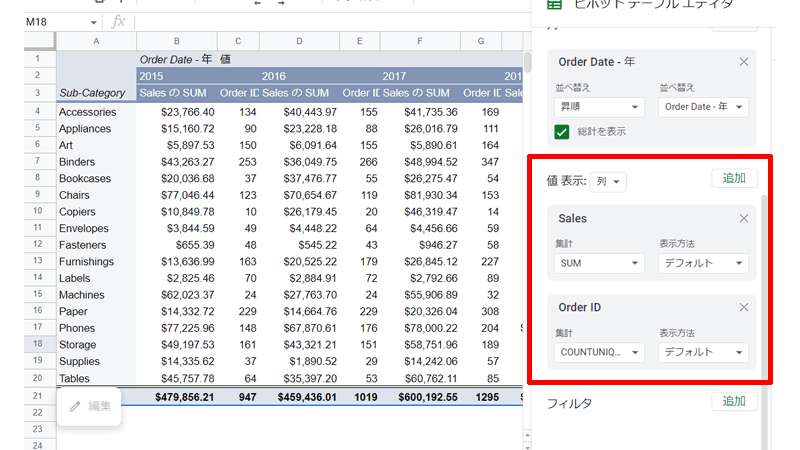
「値」には、「Sales」と「Order ID」を追加します。
「Order ID」は、「集計」を「COUNTUNIQUE」に変更して、注文数を集計してください。
これで商品ごとの売上と注文数が表示されました。
続いてさらに、特定の「州」に絞った売上と注文数を見ていきましょう。
先程の「州」ごとのテーブルでは、カリフォルニア州が最も売上が良かったので、カリフォルニア州を例に見ていきます。
なお「フィルタ」を追加する前に、ここで作成したテーブルはそのままにして、同じテーブルをコピーアンドペーストしてもう一つテーブルを作成しておいてください。
フィルタを追加する
値でフィルタ
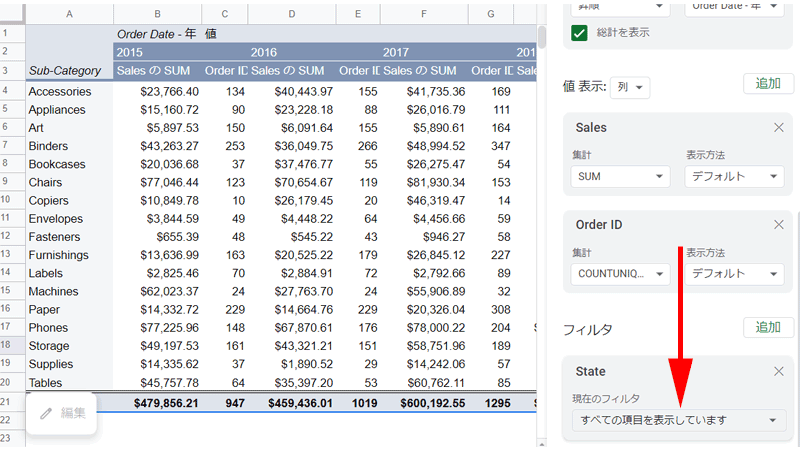
コピーアンドペーストしたテーブルで操作していきます。
「フィルタ」に「State」を追加します。
「現在のフィルタ」の「すべての項目を表示しています」と書かれた部分をクリックします。
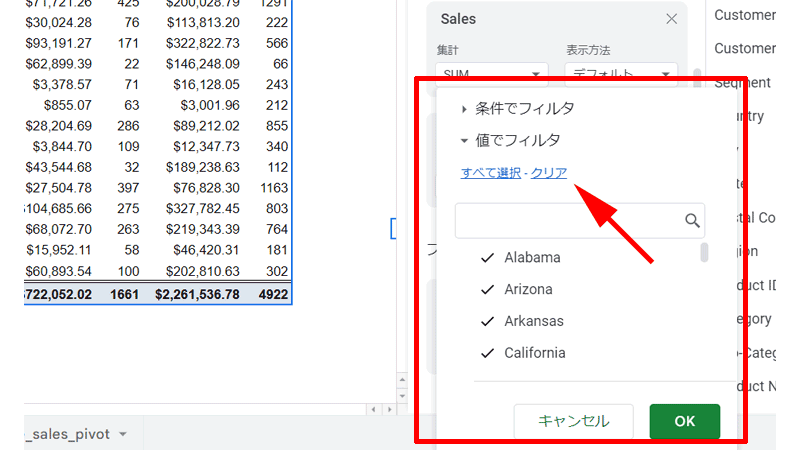
「条件でフィルタ」と「値でフィルタ」の2つがありますが、ここでは「値でフィルタ」を使用します。
この画面では下に「州名」が表示されていて、すべての「州」にチェックが入っています。
最初にこのチェックをすべて外します。
矢印の先にある「クリア」をクリックします。
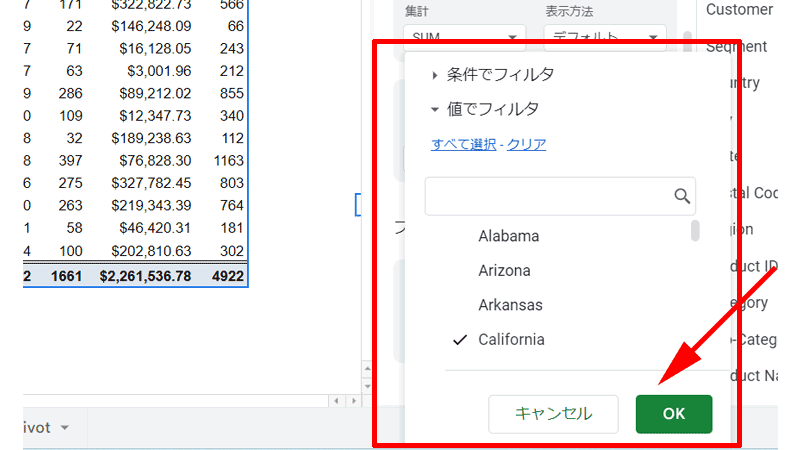
すべてのチェックが外れたら、「California」だけにチェックを入れます。
最後に「OK」ボタンを押します。
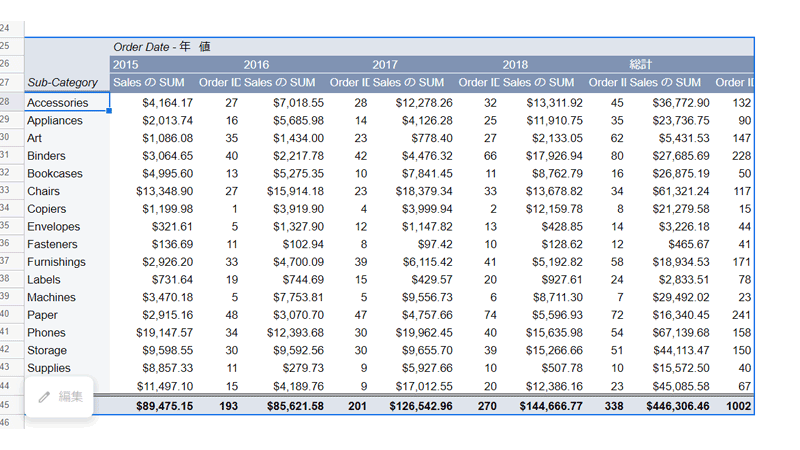
すべてのセルに「フィルタ」が適用され、カリフォルニア州だけの数値が表示されました。
条件でフィルタ
ここでは「値でフィルタ」を利用してみましたが、参考までに「条件でフィルタ」を利用する方法も見ておきましょう。
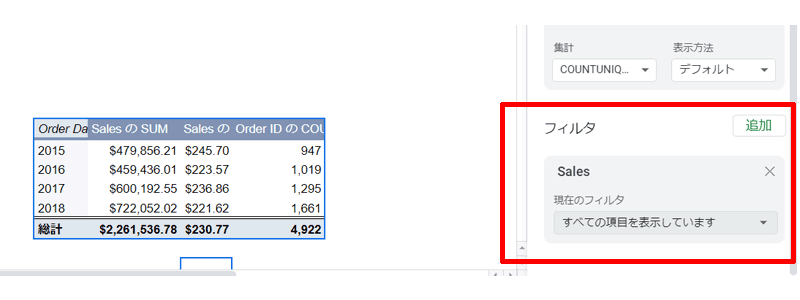
データは最初のものを使用してみます。
「フィルタ」に「Sales」を追加します。
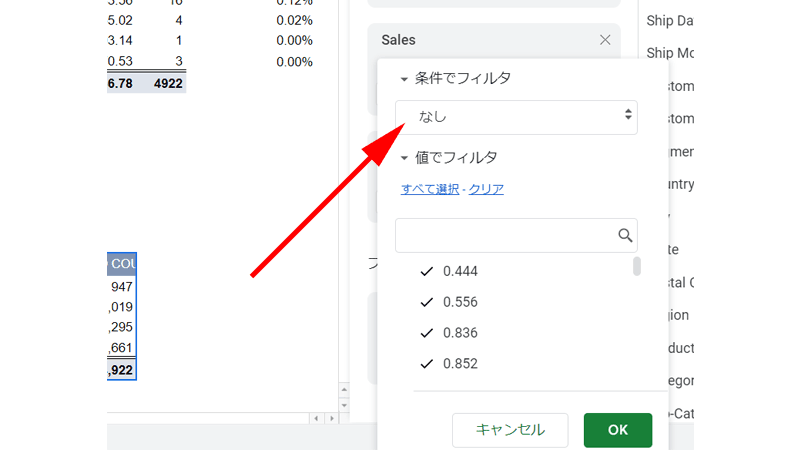
「条件でフィルタ」をクリックして、「なし」の部分をクリックします。
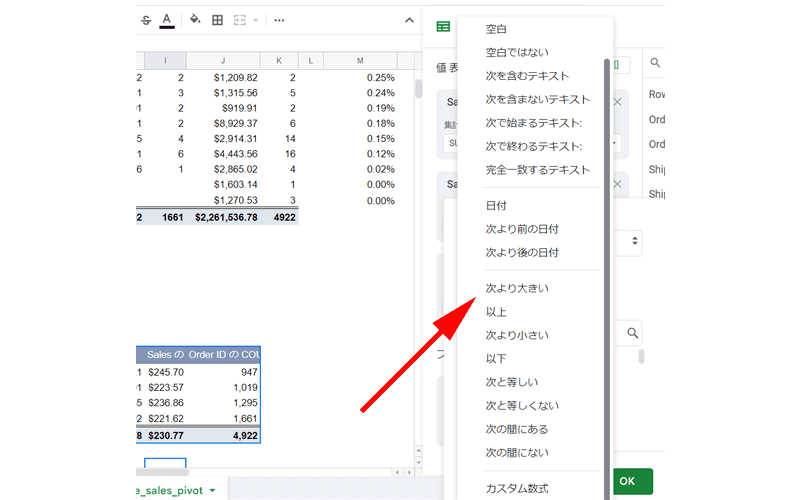
様々な項目が表示されますので、必要に応じて選択してください。
例として、「次より大きい」をクリックしてみます。
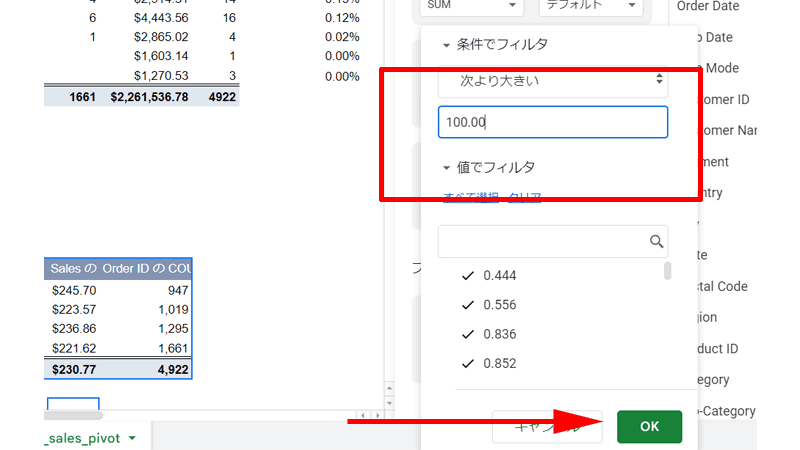
「100ドル」以上の売上に絞って集計するように指定します。
数値を入力したら最後に「OK」をクリックします。
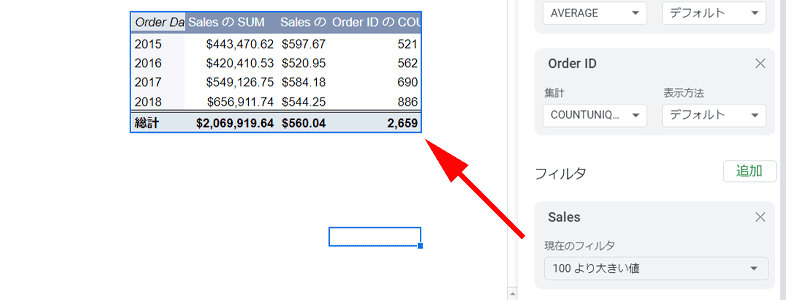
「100ドル」以上の売上に絞った結果が表示されています。
数値の指定の時に、「100」ではなく、「100.00」と入力しました。
通常は結果に違いはありませんが、もとのデータではドルの表示が少数点2桁まで記載されています。
データを分析する時は、あくまでも元のデータに基づいて数値を入力することにより、エラーを防ぐことが出来ます。
少し細かいですが、データの分析する時は、細かいことにこだわるように意識して操作するようにしてください。
計算フィールドを追加する
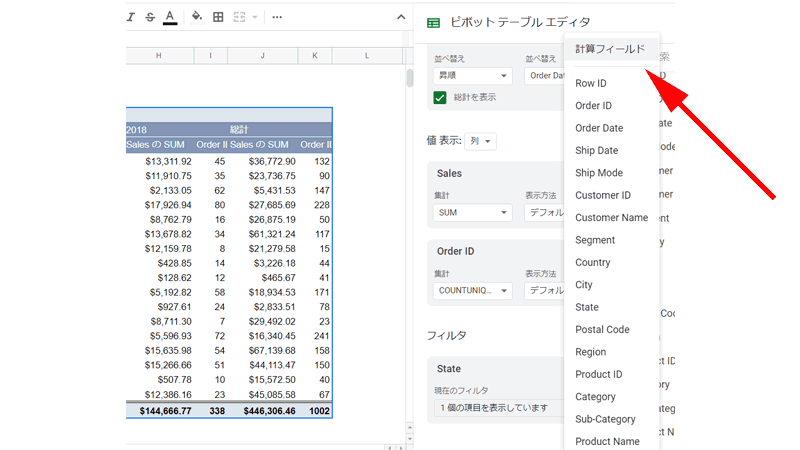
カリフォルニア州の売上の表は完成しましたが、データが正しいかどうか「計算フィールド」を使って確認してみましょう。
「値」にある「追加」をクリックすると、一番上に「計算フィールド」と表示されていますので、ここをクリックします。
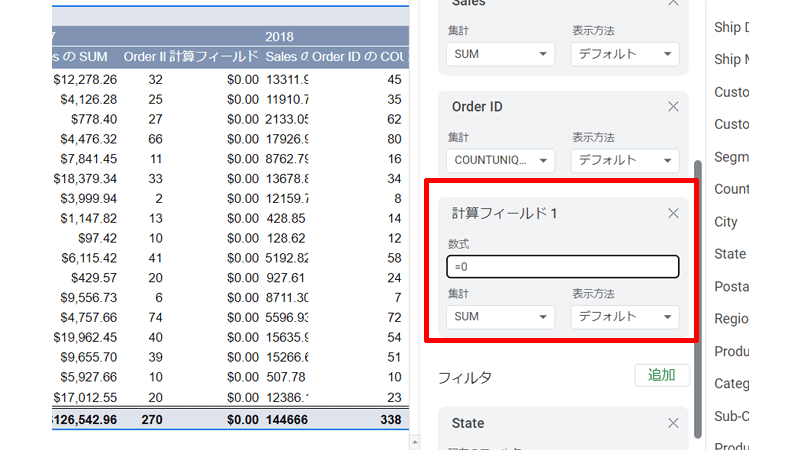
「計算フィールド」の部分に「数式」という場所がありますので、ここに数式を記入します。
ここでは元のデータにある「Sales」からカリフォルニア州の合計金額を表示させます。
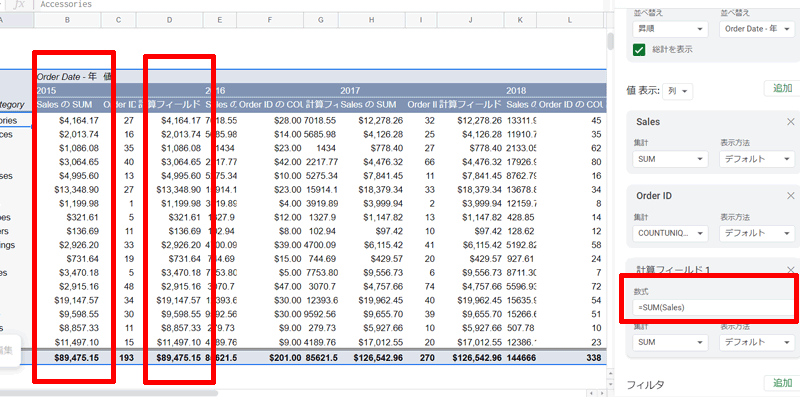
「数式」に「=SUM(Sales)」と入力します。
これで表の「計算フィールド」に元のデータから計算した、カリフォルニア州の売上が表示されます。
「SalesのSUM」と「計算フィールド」の数値が一致しているか確認してください。
間違いがなければ、ここでは「計算フィールド」は削除しても構いません。
ここでの「計算フィールド」の使い方に疑問も持たれた方もいらっしゃるかもしれません。
合計金額に間違いなどないのではと思われたのではないかと思います。
しかし今回編集したピボットテーブルは、オリジナルのピボットテーブルをコピーしたものを使用して編集しています。
表の計算や分析で間違いが起こりやすいのが実はコピーアンドペーストしたときなのです。
ここではオリジナルのピボットテーブルに複雑な計算などが含まれていないため、データに異常が発生するとは思えませんが、データエラーは思わぬ時に起こることがあります。
その思わぬ時を防ぐためにも、データの確認は非常に有効ですので、ピボットテーブルに関わらず、データを扱う時は、常に「確認すること」を意識しておきましょう。
少し面倒ですが、最初から習慣にしておくと、いつか助かるときが来ると思います。
まとめ
いかがでしたか。
少し長い文章になりましたが、一連の操作を一緒に行って頂けた方は、ピボットテーブルの使い方について十分な知識がついたと思います。
ピボットテーブルを使用して、データ分析を行うと最初には想像していなかった疑問が次々と見えて来ることがあります。
この想像していなかった疑問を見つけることがデータ分析の楽しさであり、難しさでもあります。
ぜひこれを機会にピボットテーブルを積極的に利用して、課題に対する新しい発見を見つけてみてください。
今回も最後までお読み頂き、誠にありがとうございました。


コメント